最优化计算方法(文再文)笔记
《最优化计算方法(文再文)笔记》
第一章、最优化简介
一、概述
-
最优化问题一般形式:
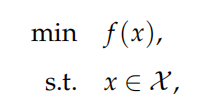
其中$x=(x_1,x_2,…,x_n)^T\in R^n$是决策变量
$f:R^n\rightarrow R$是目标函数
$\chi\in R^n$是约束集合,即可行域
s.t.是subject to,专指约束条件
但f(x)的min/max不总是存在的,此时我们关心其上下确界,即将上式改为inf(sup) f(x)
-
最优化问题分类
- 目标函数和约束函数皆为线性时,称为线性规划
- 至少有一个非线性时称为非线性规划
- 目标函数为二次函数时称为二次规划
- 还有整数规划、非光滑规划、无导数规划等。。
-
凸优化
定义:最小化问题中,目标函数和可行域分别是凸函数和凸集;相反,只要有一个不为凸,则为非凸优化问题。因为凸优化问题的任何局部最优解都是全局最优解,所以其相应的算法设计以及理论分析相对非凸优化问题简单很多。
💡 PS. 所以用凸模型对非凸问题进行转换/逼近是一个很重要的手段
第二章、基础知识
一、概述
-
矩阵范数
当p=1时,矩阵$A\in R^{m×n}$的$l_1$范数定义为:
$$
\lVert A \rVert_1=\sum_{i=1}^m\sum_{j=1}^n\vert a_{ij} \vert
$$
p=2时:
$$
\lVert A \rVert_2=\sqrt{Tr(AA^T)}=\sqrt{\sum_{i,j}a_{ij}^2}
$$
Tr(X)表示方阵的迹,即方阵的主对角线的元素之和💡 PS. 一个结论: 矩阵的2范数是该矩阵的最大奇异值(why?)
-
海瑟矩阵

-
矩阵变量函数的导数


-
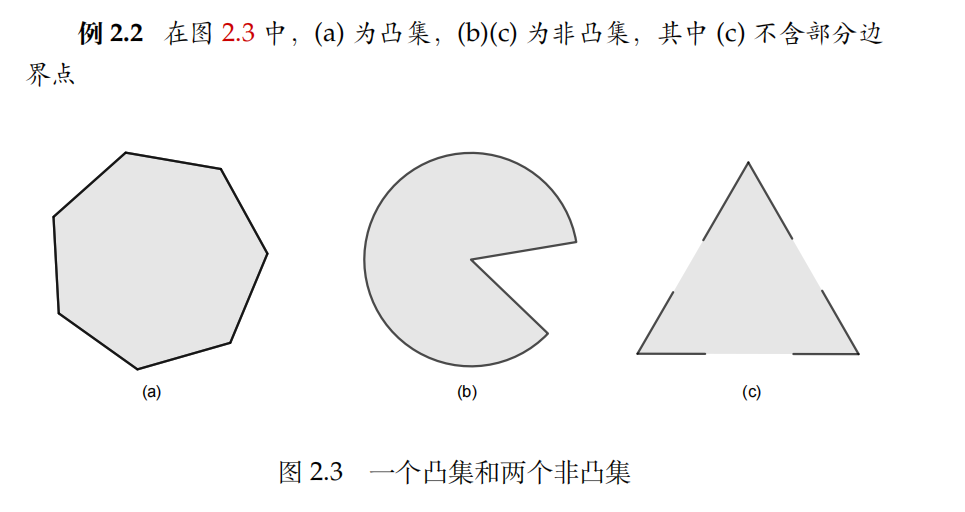
凸集
如果连接集合C中任意两点的线段都在C内,则称C为凸集
-
凸包
对于形如
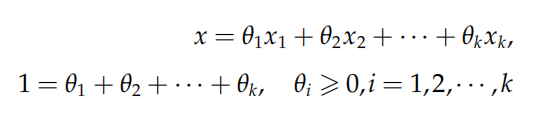
的点称为x1、x2。。。xk构成的凸组合,集合S中点所有可能的凸组合构成的集合称作S的凸包,记作convS.实际上,convS是包含S的最小的凸集。如下图所示,分别为离散点集的凸包和扇形的凸包。
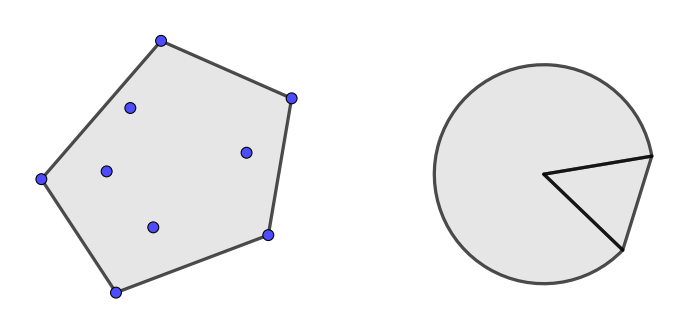
-
一些重要的凸集
- 超平面和半空间
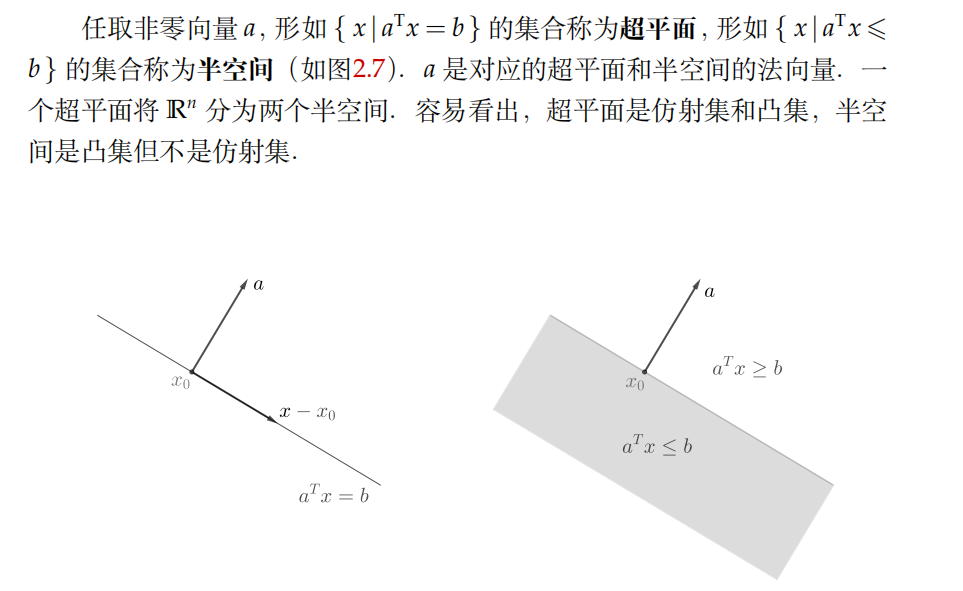
- 球、椭球、椎
常规的球、椭球、椎的定义用的是欧几里得范数,但可用其它范数进行概念推广
多面体
- (半)正定椎
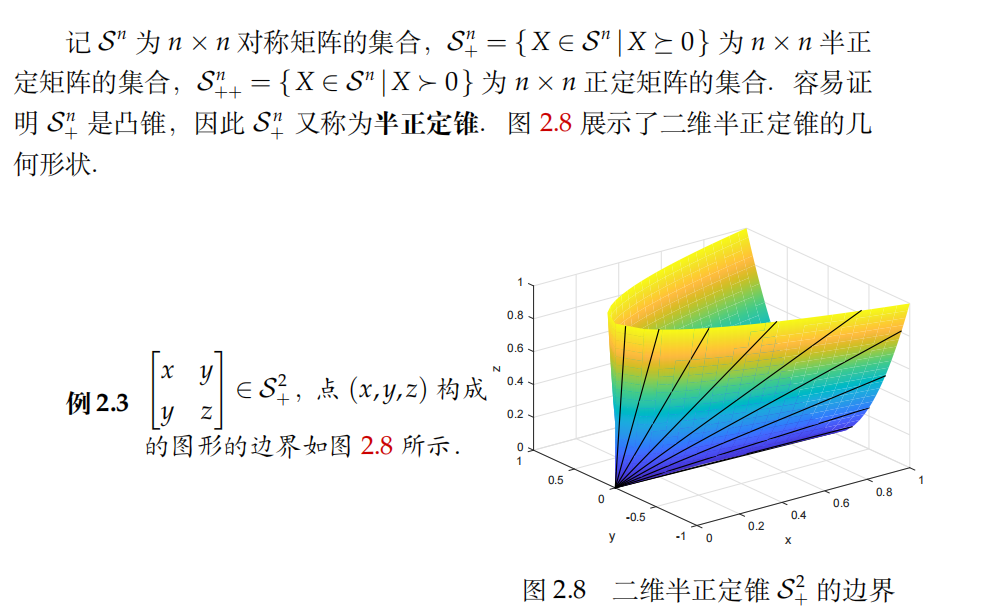
-
强凸函数

强凸函数减去一个正定二次函数仍然是凸的。和普通凸函数相比,强凸函数有更好的性质。
💡 PS. 结论:设 f 为强凸函数且存在最小值,则 f 的最小值点唯一
第三章、典型优化问题
一、线性规划
-
一般形式
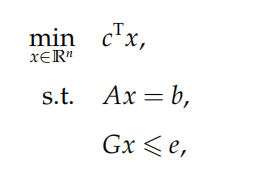
常见的两种形式:标准型(等式约束+决策变量非负)
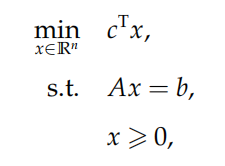
不等式形(没有等式约束)
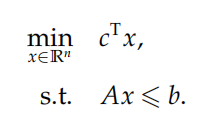
第四章、无约束优化算法
一、线搜索方法
给定当前迭代点xk,首先通过某种算法选取向量dk,之后确定正数αk,则下一步的迭代点可写作
$$
x^{k+1}=x^k+\alpha_kd^k
$$
其中dk是搜索方向,αk是步长,线搜索算法的关键就是选取好的dk和αk,为了选出合适的步长αk,我们要引入一定的要求,称之为线搜索准则,常见的有Armijo准则、Goldstein准则、Wolfe准则等
其中,用于满足Armijo准则的常用方法是回退法,其基本思想为由大到小不断试验α,直至输出一个满足Armijo准则且尽可能大的步长

二、梯度类算法
-
梯度下降法
$$ x^{k+1}=x^k-\alpha_k\nabla f(x^k) $$
-
BB算法(Barzilai-Borwein)
$$ x^{k+1}=x^k-\alpha_{BB1}^K\nabla f(x^k) $$
$$ x^{k+1}=x^k-\alpha_{BB2}^K\nabla f(x^k) $$
其中

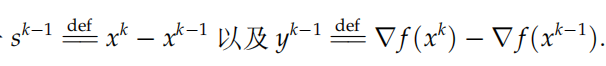
由上式可见,BB算法仅需要知道函数相邻两步的梯度信息和迭代点信息,所以BB算法的应用范围很广泛

三、次梯度算法
-
motivation:使用GDA的前提为目标函数 f(x) 是一阶可微的,但实际应用中经常会遇到不可微的函数,对于这类函数我们无法在每个点处求出梯度,但往往它们的最优值都是在不可微点处取到的。为了能处理这种情形,我们引入次梯度算法
-
次梯度算法的结构
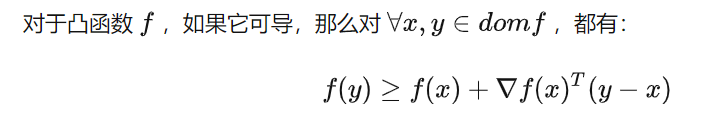
即对于凸函数来说,其切线总是在函数的下方。
类比上式可定义,给定函数f,对于任意y,如果满足:
$$ f(y)\ge f(x)+g^T(y-x) $$
则称 g 是函数 f 在点 x 处的次梯度,可见次梯度不一定唯一,也可能不存在。
将 f 在 x 处所有次梯度构成的集合称为 f 在 x 处的次微分,记作$\partial f(x)$
💡 PS. 注意:次微分是一个集合,而凸函数的次微分总是非空,即必有次梯度
假设凸函数 f 在不可微点x0处的左右导数分别为a、b,那么闭区间[a,b]中的任何一个取值都是次梯度,如$f(x)=\vert x \vert$,则
$$
g=\begin{cases}sgn(x)&x\neq0\\ any\in[-1,1]&x=0\end{cases}
$$ -
收敛性
一个常用的取法是$\alpha_k=\frac{1}{k}$,这样可保证算法的收敛性
四、牛顿类算法
-
motivation:
梯度法仅仅依赖函数值和梯度的信息(即一阶信息),如果函数 f(x) 充分光滑,则可以利用二阶导数信息构造下降方向 dk。牛顿类算法就是利用二阶导数信息来构造迭代格式的算法。由于利用的信息变多,牛顿法的实际表现可以远好于梯度法,但是它对函数 f(x) 的要求也相应变高
-
经典牛顿法
$$
x^{k+1}=x^k-\nabla^2f(x^k)^{-1}\nabla f(x^k)
$$
经典牛顿法的特点:- 步长恒为1
- 收敛速度很快,但只有局部收敛性,即初始点x0必须离真实解较近,较远时容易失效
因此在在实际应用中,人们通常会使用梯度类算法先求得较低精度的解,而后调用牛顿法来获得高精度的解
-
修正牛顿法

基本思想是对牛顿方程中的海瑟矩阵$\nabla^2f(x^k)$进行修正
五、拟牛顿类算法
-
**motivation:**拟牛顿方法不计算海瑟矩阵$\nabla^2f(x^k)$ ,而是构造其近似矩阵$B^k$或其逆的近似矩阵 $H^k$,我们希望 $B^k$ **或$H^k$仍然保留海瑟矩阵的部分性质,例如使dk仍然为下降方向
-
算法框架

-
拟牛顿矩阵更新方式
-
秩一更新(SR1)
$$ B^{k+1}=B^k+\dfrac{(y^k-B^ks^k)(y^k-B^k s^k)^{\text{T}}}{(y^k-B^kj)^{\text{T}}s^k} $$
$$ H^{k+1}=H^k+\dfrac{(s^k-H^k y^k)(s^k-H^ky^k)^{\mathrm{T}}}{(s^k-H^ky^{k})^{\mathrm{T}}y^k} $$
-
BFGS公式
$$ B^{k+1}=B^k+\dfrac{y^k(y^k)^{T}}{(s^k)^{T}y^k}-\dfrac{B^k s^k(B^k s^k)^}{(s^k)^{T}B^k s^k} $$
BFGS 公式是目前最有效的拟牛顿更新格式之一,它有比较好的理论性质,实现起来也并不复杂
-
有限内存BFGS方法
拟牛顿法虽然克服了计算海瑟矩阵的困难,但是它仍然无法应用在大规模优化问题上。一般来说,拟牛顿矩阵$B^k$ 或$H^k$ 是稠密矩阵,而存储稠密矩阵要消耗 O(n²) 的内存,这对于大规模问题显然是不可能实现的,故引入有限内存BFGS方法(L-BFGS)


六、信赖域算法
-
**motivation:**在信赖域类算法中,我们直接在一个有界区域内求解这个近似模型,而后迭代到下一个点.因此信赖域算法实际上是同时选择了方向和步长
-
形式:
我们在如下球内考虑 f(x) 的近似
$$
\Omega_k={x^k+d\mid|d|\leqslant\Delta_k}
$$

其中,mk(d)是在点x=xk处对f(x)的近似
$$ m_k(d)=f(x^k)+\nabla f(x^k)^{\mathrm T}d+\dfrac12d^{\mathrm T}B^kd $$
选取信赖域半径非常关键,它决定了算法的收敛性。考虑到信赖域半径是“对模型 mk(d) 相
信的程度”,如果 mk(d) 对函数 f(x) 近似较好,就应该扩大信赖域半径;反之减小。我们引入如下定义来衡量 mk(d) 近似程度的好坏
$$ \rho_k=\dfrac{f(x^k)-f(x^k+d^k)}{m_k(0)-m_k(d^k)} $$
如果ρk 接近于1,说明用 mk(d) 来近似 f(x) 是比较成功的,我们应该扩大 ∆k;如果 ρk 非常小甚至为负,就说明我们过分地相信了二阶模型 mk(d),此时应该缩小 ∆k

第五章、约束优化算法
一、罚函数法
-
motivation:
可行域的约束导致很多无约束算法不能直接使用(如梯度下降沿负梯度下降的点未必是可行点),而罚函数的思想是将约束条件作为惩罚项加到目标函数中,从而转换为无约束优化问题。
而这样做的原理是什么捏 —— 对于可行域外的点,惩罚项为正,即对该点进行惩罚;对于可行域内的点,惩罚项为 0,即不做任何惩罚。因此,惩罚项会促使无约束优化问题的解落在可行域内(好聪明的做法)。
-
等式约束条件罚函数

-
不等式约束
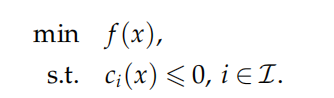
我们设计加入罚函数的目标函数为:
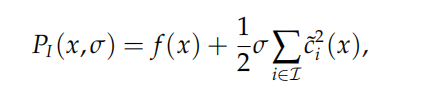
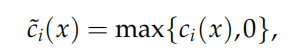
这样的罚函数只会惩罚ci(x)>0的部分,且由于函数 h(t) = (max*{t*, 0*}*)²关于 t 是可导的,因此 PI(x,σ) 的梯度也存在,则可以使用梯度类算法来求解子问题
-
内点罚函数
基本思想:普通的外点罚函数允许取可行域之外的点,只是要进行惩罚;而内点法直接不允许取可行域之外的点,即从可行域内部逼近最优解
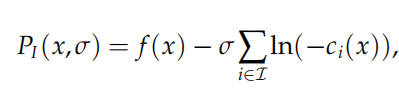
上式既做到了限制可行域,又做到了“x趋近于边界时进行惩罚”(In无穷大)
二、增广拉格朗日函数法
- 结构
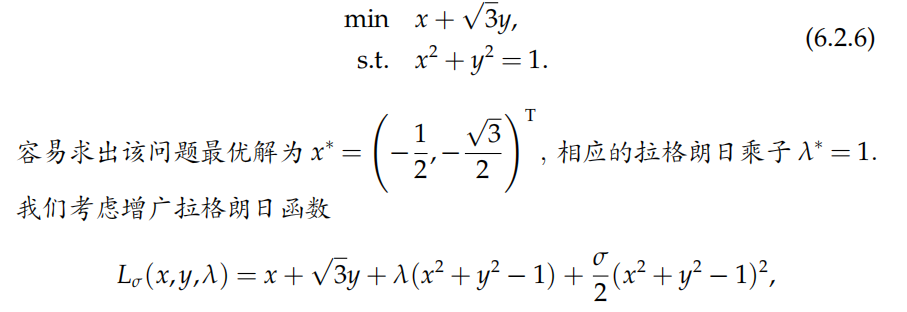
-
一般约束优化问题的增广拉格朗日函数法
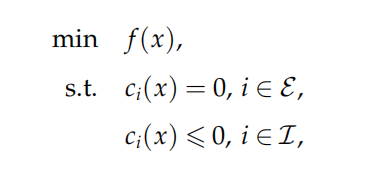
思路:引入松弛变量将不等式约束转化为等式约束和简单的非负约束,再构造增广拉格朗日函数
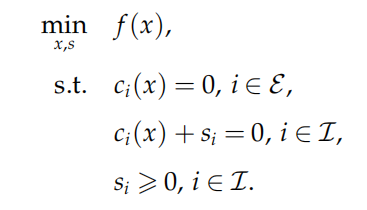
对上述问题我们可以构造出一个经典的拉格朗日函数
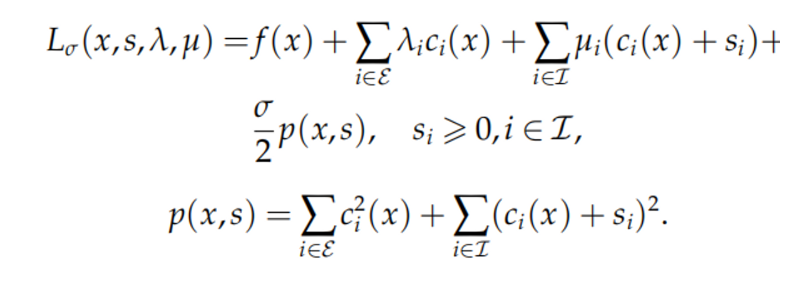
第六章、复合优化算法
一、背景
复合优化问题定义为:
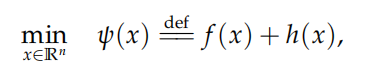
其中 f(x) 为可微函数(可能非凸),h(x) 可能为不可微函数
二、近似点梯度法
-
邻近算子
对于一个凸函数 h,定义它的邻近算子为
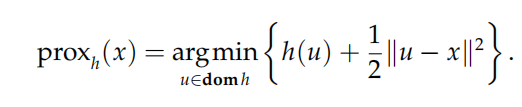
可见,邻近算子的目的是求解一个距 x 不算太远的点,并使函数值 h(x) 也相对较小
-
公式
对于一个复合优化问题
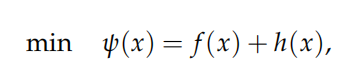
近似点梯度法的思想非常简单:注意到 ψ(x) 有两部分,对于光滑部分f 做梯度下降,对于非光滑部分 h 使用邻近算子,则近似点梯度法的迭代公式为:
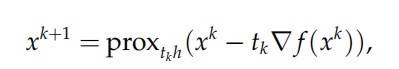
其中 tk > 0 为每次迭代的步长,它可以是一个常数或者由线搜索得出。

三、Nesterov加速算法
-
FISTA算法(可对近似点梯度算法进行加速)
FISTA 算法由两步组成:第一步沿着前两步的计算方向计算一个新点,第二步在该新点处做一步近似点梯度迭代,即
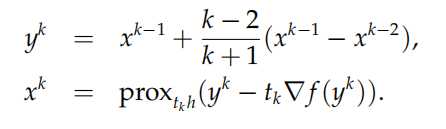

四、分块坐标下降法(block coordinate descent,BCD)
-
motivation: 实际问题中的目标函数虽可能有成百上千个自变量,求解十分困难,但当固定其中若干变量时,函数的结构会得到极大的简化,是原问题被拆分为数个只有少数自变量的子问题,这也正是BCD方法的基本思想
-
形式:
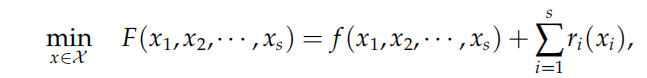
将自变量 x 拆分成 s 个变量块 x1, x2,··· , xs,函数 f 是关于 x 的可微函数,每个 ri(xi) 关于 xi 是适当的闭凸函数。 单独考虑每一块自变量时,f 有简单结构,ri 只与第 i 个自变量块有关
-
举例
考虑二元二次函数的优化问题
现在对变量 x,y 使用分块坐标下降法求解。当固定 y 时,可知当 x = 2 + y时函数取极小值;当固定 x 时,可知当 y = 1 +*x/*10时函数取极小值。故采用的分块坐标下降法为:
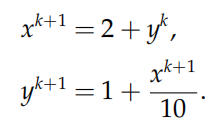
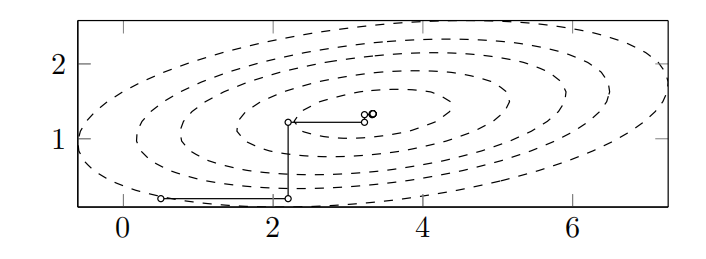
经验证,初始点为(0.5, 0.2)时,经过七次迭代就与最优解相当接近
五、对偶算法
- 对偶思想常用思路有两种:把前面的算法应用到对偶问题上,如对偶近似点梯度法;另一种是同时把原始问题和对偶问题结合起来考虑,如原始-对偶混合梯度类算法 对偶算法主要考虑如下形式的问题:
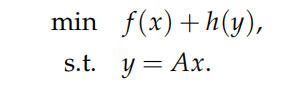
- 对偶近似点梯度法
如果我们写出上述约束优化问题的拉格朗日函数和增广拉格朗日函数
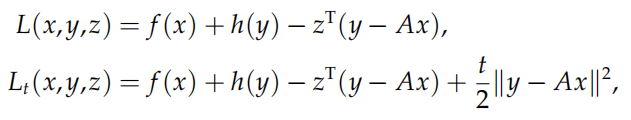
则迭代格式可以写为
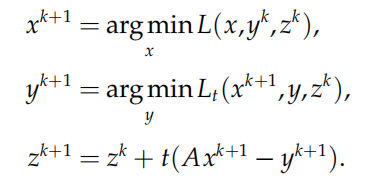
上述迭代格式又称为**交替极小化方法,**第一步迭代为在拉格朗日函数中关于 x 求极小,第二步迭代为在增广拉 格朗日函数中关于 y 求极小,第三步迭代为更新拉格朗日乘子。
- 原始-对偶混合梯度算法(primaldual hybrid gradient, PDHG)
PDGH在每次迭代时同时考虑原始变量和对偶变量的更新,这使得它在一定程度上可以有效避免单独针对原始问 题或对偶问题求解算法中可能出现的问题 仍然考虑如下形式:
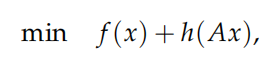
其中 f , h 是适当的闭凸函数.由于 h 有自共轭性,我们将上述问题变形为:
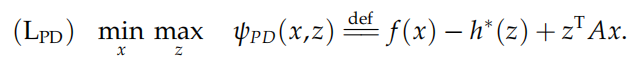
此时问题变形为一个极小-极大问题,即一个典型的鞍点问题。PDHG 算法交替更新原始变量以及对偶变量,其 迭代格式如下:
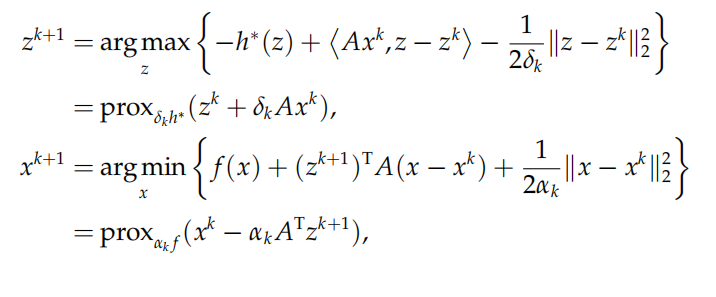
六、交替方向乘子法(alternating direction method of multipliers, ADMM)
-
定义:
本节考虑如下凸问题:
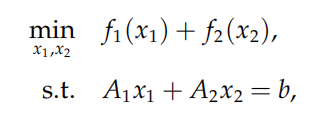
注意:很多常见的问题都可转化为上述形式
如把
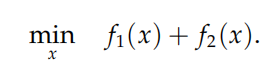
转化为:
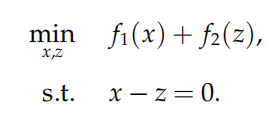
再比如对于一致性问题:
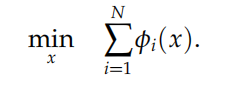
令 x = z,并将 x 复制 N 份,分别为 xi,那么问题转化为:
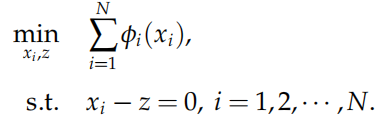
如果令$x=(x_1^\mathrm T,x_2^\mathrm T,\cdots,x_N^\mathrm T)^\mathrm T$以及$f_1(x)=\sum\limits_{i=1}^N\phi_i(x_i),\quad f_2(z)=0$ 则此问题可以化为:
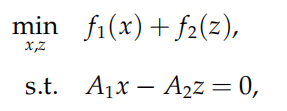
其中矩阵 A1, A2 定义为:
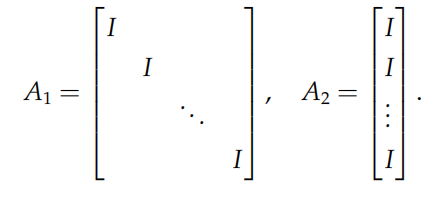
-
迭代格式
首先写出问题的增广拉格朗日函数
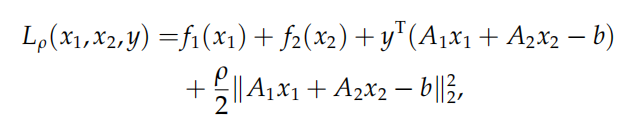
则迭代格式为: