借一道leetcode思考总结map/set的应用及区别
前言
原题是leetcode349,要求两个数组的交集
这题本身不难,主要是要考虑到:
- 原题只需求“频率”,无需考虑“顺序”,则应使用哈希表结构,而不是顺序结构+两个for暴力遍历
- 用于作键值key的是数字而非字母,所以应该用正儿八经的set/map,而不是用vector搞伪hash(否则当数字键值很大且稀疏时,vector会浪费大量空间)
- 不需要设置明确的key,所以用set,而不是map
- 不考虑顺序,所以用unordered_set
上述思路理清之后,代码自然就出来了
1 | |
由此题我们可以一窥set/map的具体使用场景,下面对其差别和应用进行简单总结
一、定义和类型
STL中的部分容器(vector、list、deque等)底层为线性序列的数据结构,故将这些容器统称为序列式容器,里面存储的是元素本身;对应的,有另外一种用<key,value>键值对方式储存数据的数据结构,我们称其为关联式容器,典型的有set类和map类容器。
这种关联式容器的motivition应该是用某种特殊的底层数据结构来代替线性序列,以避免线性结构容易导致的空间浪费问题,同时提高curd效率 – – 线性序列为O(n),那再提高就是O(log n)和O(1),对应的是啥捏?
树和hash table嘛!这也正是set\map的底层实现方式
具体如下:
| 集合 | 底层实现 | 是否有序 | 数值可重复 | 数值可更改 | curd效率 |
|---|---|---|---|---|---|
| std::set | 红黑树 | 有序 | 否 | 否 | O(log n) |
| std::multiset | 红黑树 | 有序 | 是 | 否 | O(logn) |
| std::unordered_set | 哈希表 | 无序 | 否 | 否 | O(1) |
| 集合 | 底层实现 | 是否有序 | 数值可重复 | 数值可更改 | curd效率 |
|---|---|---|---|---|---|
| std::map | 红黑树 | 有序 | key不可重复 | 否 | O(log n) |
| std::multimap | 红黑树 | 有序 | key可重复 | 否 | O(logn) |
| std::unordered_set | 哈希表 | 无序 | key不可重复 | 否 | O(1) |
其需要注意的是,set\multiset\map\multimap的实现都为红黑树,红黑树是一种平衡二叉搜索树,所以key有序且不能修改,修改key会导致整棵树的错乱;
而我们要用集合来解决hash问题时,优先使用unordered,因为其底层使用hash table,curd效率最高(只需执行一次hash function,复杂度为O(1))
二、set类说明
- 与map/multimap不同,map中存储的是真正的键值对<key, value>,set中只放value,但在底层实际存放的是由<value, value>构成的键值对(即一个元素的value同时也会标识它,value就是key)。故set中插入元素时,只需要插入value即可,不需要构造键值对
- set中的元素不可以重复,因此可以使用set进行去重
- set中的元素有序(默认升序),故可用iteration遍历set得有序序列
- set中的元素不允许修改(元素总是const)
- set中的count()方法只能返回0或1,所以其实就是个find()。。而find()返回的是查找元素的位置指针,没有则返回set.end()
- multiset与set的区别是前者中的元素可重复,其它都一样
- unordered_set与set的区别是前者中的元素不会排序
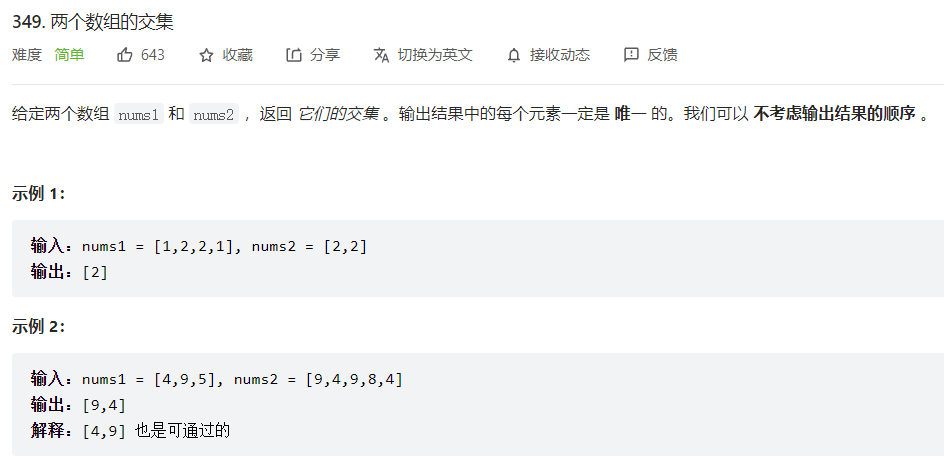
代码示例:
1 | |
运行结果:
三、map类说明
- 需要构造键值对
- map支持下标访问符,即在[]中放入key,就可以找到与key对应的value;也支持.at()方法,但二者有所不同(见下面代码)
- multimap和map的唯一不同就是:map中的key是唯一的,而multimap中key是可以重复的
- unordered_map和map : : unordered_map存储元素时是没有顺序的,只是根据key的哈希值,将元素存在指定位置,所以根据key查找单个value时非常高效
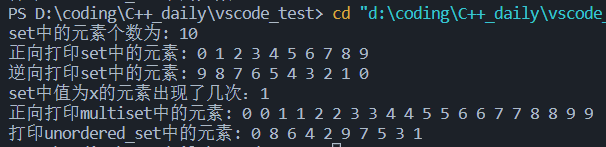
代码示例(来源: C++ STL中 set和map介绍以及使用方法)
1 | |
运行结果:
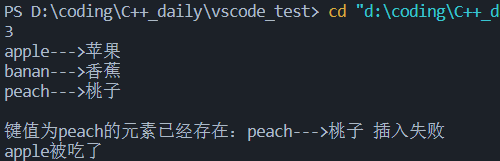
如果用at()查值,则key不在时抛出异常
1 | |

总结
1. 用set类还是map类?
如果需要建立明确的键值对应关系(如示例中的水果),那只能用map;如果只需知道“存在与否”,那用set就够了(如leetcode例题,其实没有体现一个明确的key,coding时关心的也是value而不是key)
2. 用set类还是array伪hash?
如果key分布在一个不大的连续区间内( 如26个字母),则可以直接用array,这样更快,因为set不仅占用空间比数组大,而且速度要比数组慢,set把数值映射到key上都要做hash计算的;
但如果key随机则用set,如key为分布稀疏的大数字时,用数组就非常浪费空间,只能用set。
3. 用set还是unordered_set?(map同理)
有序set(红黑树),无序unordered_set(hash table)
PS. py中的in关键字在不同结构中(tuple, list, dict, set)查找元素时效率是相差很大的,因为dict, set底层是一个hash table;而tuple, list只是一个单纯类于数组的线性结构。。