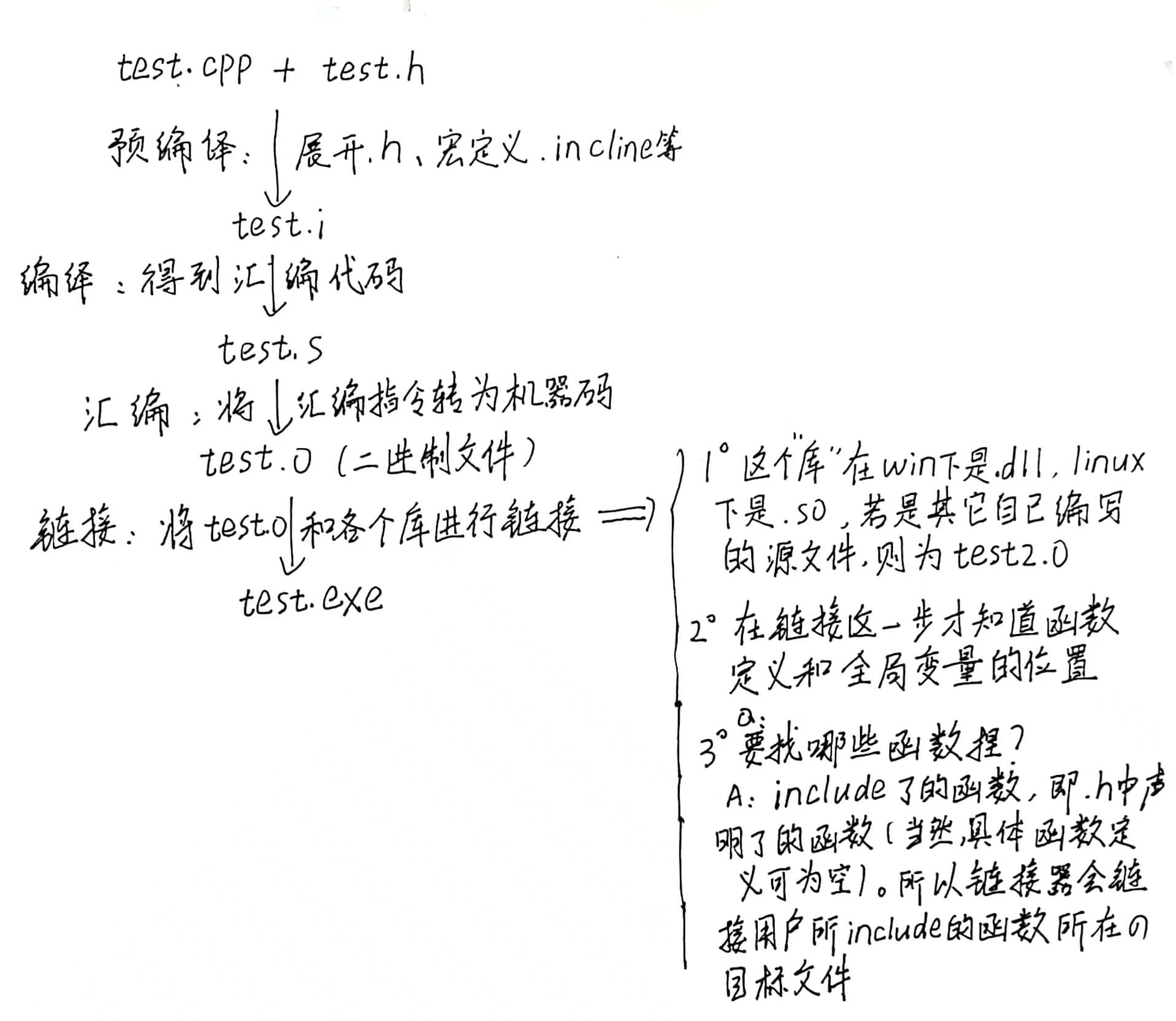
《CS106L笔记》
课程来源:Stanford-CS106L(22 fall)
课程介绍:HashMap_for_CS106L
Lecture2、Types and Structs
一、Types
- **静态语言:**有名字的东西(变量/函数)要人为给类型
- **动态语言:**运行时解释器根据current value自动给类型


Lecture3、Stream
一、cout
cout是std内嵌的输出流,它的类型是std::ostream,所以其实你也完全可以自己定义一个std::ostream类型的输出流
1 | |
上述代码会在控制台上输出1729,在out.txt中写入1730
二、cin
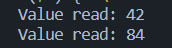
同理,可以自己创建一个std::istream类型的输入流
1 | |
输出结果:
Lecture4、Initialization and References
一、Initialization
- 注意vector两种初始化的区别

💡 PS. 其中大括号初始化被称为“统一初始化”,是C11引进的,对所有数据类型都适用,可以在declaration时立即初始化
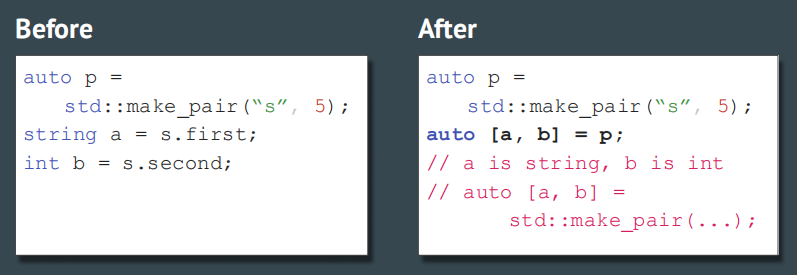
- 结构化绑定(structured binding)
idea:经典语法中,为了接收一个struct\pair,可能得用点号去一个个读取结构体里的值,这很麻烦;c17中引 入结构化绑定,可以直接用auto+中括号去接收(话说这东西matlab里不是早有了吗。。)
二、References
一个经典的引用error:想给pair中的每个值加一
1 | |
应该修改为 for (auto& [num1, num2]: nums)
Lecture5、Container
- 不要搞混vector的_size和_capacity属性

Lecture7、Classes
- STL中所有的container都是class
- 模板类(template class)
1 | |
示例:
1 | |
Lecture9、Template Functions
-
**motivation:**一个功能通用性很强的函数,要因为接收参数数据类型不同而复制粘贴多个版本吗?当然,function overloading可以简化这个问题,但仍然得复制粘贴,能不能把这个函数给一般化,从根源上解决问题捏?

-
模板函数(Template Functions)

其中typename可以设定默认参数,即写成template
在实例化使用的时候,可以显式定义Type
1
cout << myMin<int>(3, 4) << endl;当然,它还可以更聪明——我们隐式声明变量,让编译器自己推断
1
2
3
4
5
6
7template <typename T, typename U>
auto smarterMyMin(T a, U b)
{
return a < b ? a : b;
}
cout << smarterMyMin(3.2, 4) << endl;💡 PS. 注意:模板类和模板函数都是在使用(即实例化)之后才会编译!不用就不编译。 而不同的实例化编译出的结果也不一样,所以其实是编译器帮你完成了“复制粘贴多个版本”这一步。
Lecture10、Lambda Functions
1 | |

捕获列表的作用:
- [ ]是lambda引出符,编译器根据该引出符判断接下来的代码是否是lambda函数
- 捕捉上下文中的变量供lambda使用
捕获列表使用:
- [ ]表示不捕获任何变量
- [var]、[&var]分别表示以值传递和引用传递的方式捕捉变量var
- [=]、[&]分别表示以值传递和引用传递方式捕获所有父作用域的变量
1 | |
以上述代码为例,思考Lambda的意义(和普通函数相比):
-
省去定义一个完整函数、给函数命名的过程,对于这种不需要复用,且短小的函数,直接传递函数体可以增加代码的可读性。所以lambda函数又叫“匿名函数”。
💡 PS. 不要小看“省略命名”这件事,表面上看它只是少了个名字,但实质是把它看作一个普通的“操作过程”而非“对象”。就像你会给一个变量、类、函数命名,但不会单独给“把a乘上c的3次方再加123再除321”这种纯过程去命个名(除非这个操作复用率足够高),因为它抽象程度太低,即用即扔。 而所有值得去命名的东西,都应该是会复用且抽象程度足够的。我认为这是编程中的一种哲学思想。 如:一个普通操作复用程度足够高时(比较int a、int b大小),就把它抽象为一个函数(max函数);而这个函数复用率够高时,就进一步抽象为template function
-
允许函数作为一个对象进行传递:lambda也可以命名,然后将其进行传递。这种方式和传统的函数指针比起来更加简明。
-
引入闭包:闭包是指将当前作用域中的变量通过值或者引用的方式封装到lambda表达式当中,成为表达式的一部分,它使你的lambda表达式从一个普通的函数变成了一个带隐藏参数的函数。
常见应用场景:
-
用于stl算法库
1
2
3
4// for_each应用实例
int a[4] = {11, 2, 33, 4};
sort(a, a+4, [=](int x, int y) -> bool { return x%10 < y%10; } );
for_each(a, a+4, [=](int x) { cout << x << " ";} );💡 PS. foreach()这个东西在#include
里,是个template function,其前两个参数是begin和end指针 -
*用于多线程场景*
-
作为函数的入参
1 | |
Lecture12、Specical Member Functions(6个)
-
介绍:
C++中类的特殊成员函数有6个,对于一个类
1
2
3
4
5
6
7
8
9class A
{
public:
void setData(int data) { m_data = data; }
int getData(void) { return m_data; }
private:
int m_data;
};编译器会自动帮我们生成这些特殊成员函数,所以类A的定义等价于如下,
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17class A
{
public:
A() {}; // 默认构造函数
A(const A& other) { m_data = other.m_data; } // 拷贝构造函数
A& operator=(const A& other) { m_data = other.m_data; return *this; } // 拷贝赋值构造函数
~A() {} // 析构函数
A(A&& other) { m_data = other.m_data; } // 移动构造函数
A& operator=(A&& other) { m_data = other.m_data; return *this; } // 移动赋值构造函数
void setData(int data) { m_data = data; }
int getData(void) { return m_data; }
private:
int m_data;
}; -
拷贝构造函数(copy constructor)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16#include<iostream >
using namespace std;
class Complex
{
public:
double real, imag;
Complex(double r, double i) {
real= r; imag = i;
}
};
int main(){
Complex cl(1, 2);
Complex c2 (cl); //用拷贝构造函数初始化c2
cout<<c2.real<<","<<c2.imag; //输出 1,2
return 0;
}如果用户自己编写了复制构造函数,则默认复制构造函数就不存在了
-
拷贝赋值构造函数(copy assignment constructor)
对“=”进行重载,作用是让两个已经初始化完毕的类进行拷贝
1
2myclass A,B;
A = B;
💡 PS. 上述两个构造函数的应用其实都非常非常广泛 —— 别忘了,stl的容器全都是类! vector
- 深拷贝与浅拷贝
-
大部分正常情况下只需要浅拷贝(如基本数据类型、简单的类),int A = B,就是B所在内存中的数据按二进制位(bit)复制到A所在的内存
-
深拷贝用于什么情况捏?假设有某个类有两个实例A、B,类持有**动态分配的内存/指向其他数据的指针,**那此时就不能简单地A = B,否则A中的指针也会指向B中指针对应的内存,这样一来,一修改A,B也会随之被修改,没达到拷贝的效果。
正确做法是,去显式地定义一个拷贝构造函数,它除了会将原有对象的所有成员变量拷贝给新对象,还会为新对象再分配一块内存,并将原有对象所持有的内存也拷贝过来。这样做的结果是,原有对象和新对象所持有的动态内存是相互独立的,更改一个对象的数据不会影响另外一个对象。
💡 PS. 如果一个类拥有指针类型的成员变量,那么绝大部分情况下就需要深拷贝,因为只有这样,才能 将指针指向的内容再复制出一份来,让原有对象和新生对象相互独立,彼此之间不受影响。如果类的成 员变量没有指针,一般浅拷贝足矣。
- 深拷贝的开销往往比浅拷贝大(除非没有指向动态分配内存的属性),所以我们倾向于尽可能使用浅拷贝
-
左值、右值
-
左值(lvalue):表达式结束后依然存在的持久对象
-
右值(rvalue):表达式结束后就不再存在的临时对象。字面量(字符字面量除外)、临时的表达式值、临时的函数返还值这些短暂存在的值都是右值。
更直观的理解是:有变量名的对象都是左值,没有变量名的都是右值。(因为有无变量名意味着这个对象是否在下一行代码时依然存在)
-
💡 PS. 值得注意的是,字符字面量是唯一不可算入右值的字面量,因为它实际存储在静态内存区,是持久存在的
-
右值引用
右值引用类型 &&用于匹配右值,左值引用&用于匹配左值
1
2
3
4
5
6
7
8
9
10
11
12//左值引用形参=>匹配左值
void Vector::Copy(Vector& v){
this->num = v.num;
this->a = new int[num];
for(int i=0;i<num;++i){a[i]=v.a[i]}
}
//右值引用形参=>匹配右值
void Vector::Copy(Vector&& temp){
this->num = temp.num;
this->a = temp.a;
}一个对应关系:
左值 —— 左值引用 —— 深拷贝
右值 —— 右值引用 —— 浅拷贝
这和深浅拷贝的定义是相符的,因为右值临时存在,用完就丢,所以就不存在拷贝之后动态分配内存冲突的问题,那就只需要浅拷贝;左值反之
-
强转右值std::move()
1
2
3
4
5
6
7
8
9
10void func(){
Vector result;
//...DoSomething with result
if(xxx){ans = result;}
//现在我希望把结果提取到外部的变量ans上
//...Do other things without result
return;
}result赋值给ans后就不再被使用,因此我们期望它调用的是移动赋值构造函数。 但是result是一个有变量名的左值类型,因此ans = result 调用的是拷贝赋值构造函数而非移动赋值构造函数
解决办法:用c++11提供的move强转右值
1
2
3
4
5
6
7
8
9
10void func(){
Vector result;
//...DoSomething with result
if(xxx){ans = std::move(result);}
//调用的是移动赋值构造函数
//...Do other things without result
return;
} -
右值引用类型和右值的关系
1
2
3
4
5
6
7
8
9
10
11void test(int& o) {std::cout << "为左值。" << std::endl;}
void test(int&& temp) {std::cout << "为右值。" << std::endl;}
int main(){
int a;
int&& b = 10;
//请分别回答:a、std::move(a)、b 分别是左值还是右值?
test(a);
test(std::move(a));
test(b);
}答:a是左值,std::move(a)是右值,但b却是左值。
在这里b虽然是 int&& 类型,但却因为有变量名(即可持久存在),被编译器认为是左值。
结论:右值引用类型只是用于匹配右值,而并非表示一个右值。因此,尽量不要声明右值引用类型的变量,而只在函数形参使用它以匹配右值。
-
补充:构造函数之后的冒号
c++的语法特性,冒号后面跟的是赋值
1
2
3
4
5
6
7
8A(int aa, int bb):a(aa), b(bb) {}
//相当于
A(int aa, int bb)
{
a=aa;
b=bb;
}
Lecture13、RAII and Smartpointer
-
motivation
手动申请动态内存+手动释放会有什么问题呢?
1
2
3
4
5Person* p = new Person(id_number);
//do something
delete p;若在申请完内存之后,do something的过程中用抛出了异常(throw an exception),那就无法执行delete p,从而造成内存泄漏(leak memory)。 此问题还不止是指针,文件的open和close、线程的try_lock和unlock、套接字的socket和close,都是这样的“配套操作”,
为了解决这个问题,我们可以使用RAII(Resource Acquisition is Initalization)原则,其核心思想是:
- All resources used by a class should be acquired in the constructor
- All resources used by a class should be released in the destructor
即key idea是利用**“对象的析构是自动完成的”** —— 由于对象在go out of its own scope后,析构函数总是会被自动调用,那么只要遵循上面两点原则,就可以避免内存泄漏了
-
实例
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17#include <iostream>
#include <memory>
int main()
{
for (int i = 1; i <= 10000000; i++)
{
int32_t *ptr = new int32_t[3];
ptr[0] = 1;
ptr[1] = 2;
ptr[2] = 3;
//delete ptr; //假设忘记了释放内存
}
system("pause");
return 0;
}可想而知会占据极大的内存空间
我们将其改进为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35#include <iostream>
#include <memory>
template<typename T>
class auto_release_ptr
{
public:
auto_release_ptr(T *t) :_t(t){};
~auto_release_ptr()
{
delete _t;
};
T * getPtr()
{
return _t;
}
private:
T *_t;
};
int main()
{
for (int i = 1; i <= 10000000; i++)
{
auto arp = auto_release_ptr<int32_t>(new int32_t[3]);
int32_t *ptr = arp.getPtr();
ptr[0] = 1;
ptr[1] = 2;
ptr[2] = 3;
}
system("pause");
return 0;
}**思路:**将申请的int指针托管给模板类auto_release_ptr,再去声明一个普通int指针指向申请的内存空间(通过接收类成员函数的返回值实现),从而让ptr 与 auto_release_ptr 拥有了相同的生命周期,每次for循环自动析构释放,非常妙。
-
智能指针
(1)std : : unique_ptr
1
2
3
4
5
6
7
8
9
10
11
12
13//普通指针
void raw_ptr_fun(){
Node* n = new Node;
//do things with n
delete n;
}
//智能指针
void smart_ptr_fun(){
std::unique_ptr<Node> n(new node);
//do things with n
//automatically freed!
}特点:
- 无法进行左值的赋值或赋值构造,但允许临时右值赋值构造和赋值(用move语义)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15unique_ptr<string> p1(new string("I'm Li Ming!"));
unique_ptr<string> p2(new string("I'm age 22."));
cout << "p1:" << p1.get() << endl;
cout << "p2:" << p2.get() << endl;
//p1 = p2; // error!禁止左值赋值
//unique_ptr<string> p3(p2); // error!禁止左值赋值构造
unique_ptr<string> p3(std::move(p1));
p1 = std::move(p2); // 使用move把左值转成右值就可以赋值了
cout << "p1 = p2 赋值后:" << endl;
cout << "p1:" << p1.get() << endl;
cout << "p2:" << p2.get() << endl;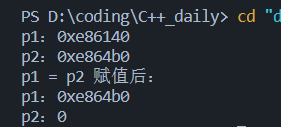
💡 PS. 在这里也可以看到,把p2 move成临时值之后,一赋值给p1,它就被释放掉了,内存地址为nullptr
- 排它式资源享用:两个指针不能指向同一个资源
1
2
3
4
5
6
7
8
9
10
11unique_ptr<string> p1;
string *str = new string("智能指针的内存管理陷阱");
p1.reset(str); // p1托管str指针
{
unique_ptr<string> p2;
p2.reset(str); // p2接管str指针时,会先取消p1的托管,然后再对str的托管
cout << "p2:" << *p2 << endl;
}
// 此时p1已经没有托管内容指针了,为NULL,在使用它就会内存报错!
cout << "p1:" << *p1 << endl;
(2)std : : shared_ptr
idea: 记录引用特定内存对象的智能指针数量,当复制或拷贝时,引用计数加1,当智能指针析构时,引用计数减1,如果计数为零,代表已经没有指针指向这块内存,那么我们就释放它
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
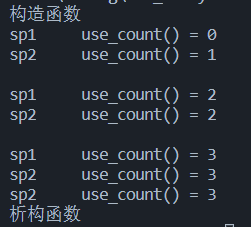
35class Person {
public:
Person() {
cout << "构造函数 \\t " << endl;
}
~Person() {
cout << "析构函数 \\t " << endl;
}
};
int main()
{
shared_ptr<Person> sp1;
shared_ptr<Person> sp2(new Person());
// 获取智能指针管控的共享指针的数量 use_count():引用计数
cout << "sp1 use_count() = " << sp1.use_count() << endl;
cout << "sp2 use_count() = " << sp2.use_count() << endl << endl;
// 共享,即sp1和sp2共同托管同一个指针
sp1 = sp2;
cout << "sp1 use_count() = " << sp1.use_count() << endl;
cout << "sp2 use_count() = " << sp2.use_count() << endl << endl;
shared_ptr<Person> sp3(sp1);
cout << "sp1 use_count() = " << sp1.use_count() << endl;
cout << "sp2 use_count() = " << sp2.use_count() << endl;
cout << "sp2 use_count() = " << sp3.use_count() << endl;
return 0;
}
(3)std : : weak_ptr
TO-DO
-
智能指针初始化方式
常规初始化方式有两种:显式调用new、使用make_unique()函数

Q: Which is better?
A: std : : make_unique和std : : make_shared更好,因为显式调用new会分配两次内存(一次给up,一次是new T)
Assignment:HashMap
-
using关键字
可用于设置别名,功能类似于typedef
1
using value_type = std::pair<const K, M>; -
explicit关键字
修饰class的constructor,令其只能显式声明,不能隐式转换or赋值初始化
1
2
3
4explicit HashMap(size_t bucket_count, const H& hash = H());
HashMap<int, int> map(1.0); // double -> int conversion not allowed.
HashMap<int, int> map = 1; // copy-initialization, does not compile. -
成员函数末尾加const —— 常成员函数
const成员函数可以使用类中的所有成员变量,但是不能修改它们的值,这种措施主要目的还是保护数据。通常将 get类型的函数(get_value、get_size。。)设置为常成员函数。
1
2inline size_t size() const noexcept;
inline bool empty() const noexcept;
💡 PS.
- 需要强调的是,必须在成员函数的声明和定义处同时加上 const 关键字。
char *getname() const和char *getname()是两个不同的函数原型,如果只在一个地方加 const 会导致声明和定义处的函数原型冲突。 - 区分一下 const 的位置:
- 函数开头的 const 用来修饰函数的返回值,表示返回值是 const 类型,也就是不能被修改,例如
const char * getname() - 函数头部的结尾加上 const 表示常成员函数,这种函数只能读取成员变量的值,而不能修改成员变量的值,例如
char * getname() const
- 函数开头的 const 用来修饰函数的返回值,表示返回值是 const 类型,也就是不能被修改,例如
- 需要强调的是,必须在成员函数的声明和定义处同时加上 const 关键字。
-
noexcept关键字
程序员在语义层面声明“我保证这个函数不会异常,编译器你不用检查了”,之后编译器就不会对该函数进行异常检查,也没办法实施try-catch操作
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17#include <iostream>
using namespace std;
void func_not_throw() noexcept {
throw 1;
// noexcept函数中本不应有throw,没意义,但编译器不会检查是否有throw
// 所以编译通过,不会报错(可能会有警告)
}
int main() {
try {
func_not_throw(); // 直接 terminate,不会被 catch
} catch (int) {
cout << "catch int" << endl;
}
return 0;
} -
注意:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28#include <iostream>
using namespace std;
class CTest
{
public:
void show() const
{
cout << "const" << endl;
}
void show()
{
cout << "normal" << endl;
}
};
int main()
{
CTest a;
a.show();
const CTest b;
b.show();
system("pause");
return 0;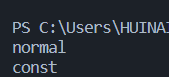
这两个show函数可不是重载!**重载函数的形参必须不同!!**这俩就不是同一个函数原型(因为加了const,是常成员函数)
那么调用的时候如何区分这俩捏?
它们各自被调用的时机为:如果定义的对象是常对象,则调用的是const成员函数,如果定义的对象是非常对象,则调用重载的非const成员函数。
💡 PS. 不过从另一个角度来理解,也可以把它俩看成重载 —— 首先理解下函数签名:它包含着一个函数的信息,包括**函数名、参数类型、参数个数、顺序以及它所在的类和命名空间,**两个函数只有在签名不同时才能被区分。
那上面两个show( )的签名到底哪里不同了捏? 答案是参数类型,每个成员函数的参数中其实自带this指针,只不过藏起来了,谁调用成员函数,this 就指向谁。而成员函数尾巴上的const,实质修饰的是this指针! 当a调用show方法时,函数签名为show(a){},即a传给this指针,一看,诶!a为非常对象,对应普通this指针,即非const版本的show();b同理。 -
typename关键字作用
1
2
3
4template <typename Map, bool IsConst>
typename HashMapIterator<Map, IsConst>::reference HashMapIterator<Map, IsConst>::operator*() const {
return _node->value;
}-
作为类型声明,效果完全等同于class —— 代码中的typename Map等同于class Map,它俩都是告诉编译器,“我后面跟着的这个是个类型名称,而不是成员变量或成员函数”。(这好像也能映证“模板函数在实例化后才会被编译”)
-
作为修饰关键字:
1
2
3
4template<typename T>
void fun(const T& proto){
T::const_iterator it(proto.begin());
}**motivation:**虽然人类编程者一眼就知道const_iterator是个类型名称,但编译器不知道呀,万一它是个变量呢?在模板实例化之前,完全没有办法来区分它们,所以这个写法是会error的! 怎么办捏? 这时候就需要使用typename关键字来修饰,编译器才会将该名称当成是类型
1
typename T::const_iterator it(proto.begin());这样编译器就可以确定T: :const_iterator是一个类型,而不再需要等到实例化时期才能确定,因此消除了前面提到的歧义。
💡 PS. 总结:同时使用模板类T和域解析符: : 时,就得加typename
-
-
模板类中的成员函数(往往也是模板函数)的具体实现通常也会放在.h中,除非函数太多太长
-
两个指针相减 = 两指针的地址差值/sizeof(数据类型),即得到的结果就是两指针之间间隔的元素个数
注意: 不需要人为手动去除sizeof哈!减号自动会完成这个操作(c和cpp中都是)
-
运算符重载
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58#include <iostream>
#include <iomanip>
using namespace std;
//秒表类
class stopwatch{
public:
stopwatch(): m_min(0), m_sec(0){ }
public:
void setzero(){ m_min = 0; m_sec = 0; }
stopwatch run(); // 运行
stopwatch operator++(); //++i,前置形式
stopwatch operator++(int n); //i++,后置形式
friend ostream & operator<<( ostream &, const stopwatch &);
private:
int m_min; //分钟
int m_sec; //秒钟
};
stopwatch stopwatch::run(){
++m_sec;
if(m_sec == 60){
m_min++;
m_sec = 0;
}
return *this;
}
stopwatch stopwatch::operator++(){
return run();
}
stopwatch stopwatch::operator++(int n){
stopwatch s = *this;
run();
return s;
}
ostream &operator<<( ostream & out, const stopwatch & s){
out<<setfill('0')<<setw(2)<<s.m_min<<":"<<setw(2)<<s.m_sec;
return out;
}
int main(){
stopwatch s1, s2;
s1 = s2++;
cout << "s1: "<< s1 <<endl;
cout << "s2: "<< s2 <<endl;
s1.setzero();
s2.setzero();
s1 = ++s2;
cout << "s1: "<< s1 <<endl;
cout << "s2: "<< s2 <<endl;
return 0;
}C++运算符重载,本质上等于定义一个成员函数(实际上也可能是全局函数)。例如a+b,本质上等同于调用函数**「a.operator+(b)」**,该函数的名字叫「operator+」 ++的重载分为前置和后置情况,a = ++b;(前置), a = b++;(后置)。因为符号一样,所以给后置版本加一个int形参作为区分,这个形参是0,但是在函数体中是用不到的,只是为了区分前置后置。 至于为啥加了个形参就能区分前后缀,没想懂,也没查到资料
-
this指针
1
2
3
4template <typename K, typename M, typename H>
HashMap<K, M, H>::~HashMap() {
clear();
}这里调用clear()用不用加this指针? 答案是可加可不加,编译器都会隐式调用
Q: 什么时候this指针是必不可少的捏?
A: 当你在对象方法里需要明确使用自己的时候,比如区分同名的形参和成员变量
-
当一个函数的返回值为引用类型时,不要return 某个在stack上的变量的引用!(否则该函数一退出,stack就释放,引用就掉了)
-
遍历类的实例化对象(自定义类的迭代器)
1 | |
Q: lhs是自定义的HashMap类,其成员变量不只是装有<key, mapped>的链表,还有各种int size、int load_factor等属性啊,为啥可以直接用 : 进行range based for loop捏?或者说,为啥只会循环到想要的链表,而不会访问其它成员变量捏?
A: 之所以会有上述误区,是因为把range based循环当成了编译器内置运算符,事实上是自己要为该类定义一个iterator类!
range based的 : 符号只是一种简略写法,它的源码实现大概为:
1 | |
由此可见,自定义的iterator类至少要有5个功能:
- begin( )
- end( )
- 重载++、*、! =三个运算符
其中begin( )、end( )返回类型就是iterator
现在就可以理解为啥可用range based循环获取自定义类中想要的数据了 —— iterator功能全是用户自己定义的,想获取啥就获取啥捏
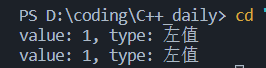
- Q: 右值引用的类对象的属性也是右值吗?
1 | |
A: 将类对象用move()强转为右值,并不影响类中成员变量的左右值属性,该是啥还是啥
-
对上面这个问题的进一步深层理解:
Q: 被move()过的变量会被编译器自动给销毁吗?如果会,那为啥还要手动让rhs._buckets_array[i] 指向nullptr?如果不会,那强转右值有啥意义啊?
A: 变量会被怎么处理,与它是否被move()过没半毛钱关系,move()并不改变变量本身,只是额外提供了一个return的右值,这一点看源码即可明白
1
2
3
4
5
6// FUNCTION TEMPLATE move
template <class _Ty>
remove_reference_t<_Ty>&& move(_Ty&& _Arg) noexcept {
return static_cast<remove_reference_t<_Ty>&&>(_Arg);
}
//只是把返回值用static_cast强制转换成右值,但传入的原变量该是啥还是啥那move()的意义是啥捏 —— 多提供一种数据类型,用于重载函数的形参匹配。 说白了,就是手动帮助编译器选择重载函数,同时向编译器发誓再也不碰这个对象! 那这个作用的motivation又是啥捏 —— 若没有右值引用,那拷贝函数就要分成deep_copy()和shallow_copy()两个版本来写,且每次都要手动显式调用 —— 这既麻烦,又容易出错;但利用重载写成copy(const T& val)和copy(T&& val)后,就可以让编译器自动调用。而若用户自己发现,诶!这个指针a虽然是左值,但我之后不用了,可以直接浅拷贝,ok,那用move()强转一次即可,即所谓的“手动帮编译器选择重载函数”。 回到一开始的问题,经move()的变量会被销毁咩? 那得看移动构造函数/移动赋值构造函数是咋实现的:在上面HashMap的那个移动构造函数中,手动释放了指针并让size清零(这也是符合实际写代码的思路的,既然认定了“这个对象不会再碰”,那就应该释放它,留着既占空间、又有修改内存的风险);反之,如果移动构造函数中没释放右值,那它就原封不动地在那儿 —— 说到底,还是与变量是左值/右值本身没半毛钱关系,而是取决于SMF中怎么去处理这个变量
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16void test_fun(const int& val){
cout << "value: " << val<< ", type: 左值" << endl;
}
void test_fun(const int&& val){
cout << "value: " << val<< ", type: 右值" << endl;
}
int main()
{
int a = 1;
int b = move(a);
test_fun(a); //a没有被销毁
test_fun(b);
return 0;
}