《CS61C笔记》
课程来源:UCB-CS61C(20 summer)
《CS61C笔记》@qlhhahaha
Q: C++完全兼容C,为什么C还有单独存在的必要?
A:
一、大道至简,多并非好:用更少的资源做同样的事(单片机、底层芯片资源有限)
二、跨平台兼容性:仅有C能做到完美跨平台(这也是因为它简单,C++版本太多、标准协议都不统一,老一点的机器可能根本就不支持C17甚至C11等现代语法)
三、C++太难,人力成本高,学习陡峭、维护困难
(新增:四、两种语言在实际应用中的使用思路其实差异非常大,C编程者写C++只能写出C with class,属于有了大炮还用棒棒戳;C++者写C会发现技能全被封印,不知如何用平A打boss——总之一句话,让剑宗和气宗各自去做自己的事吧)
Lecture4、C Memory Management
- sizeof( )可以查看数组的大小,但不能查看指针所指区域的大小(但这仍然不应成为一种普遍用法,更好的做法是使用两个参数:数组指针和数组长度)
1 | |

- 一种常见的内存泄漏bug —— 改变指针却未留副本
1 | |
Lecture6、Assembly Language, RISC-V Intro
- 主流架构

- **x86:**属于CISC(complex instruction set computer),intel和AMD都使用x86架构,MacBook和pc(Core i3, i5, i7, M)皆使用x86指令集
- **ARM:**属于RISC(reduced instruction set computer),用于智能手机、树莓派、嵌入式系统
- **risc-V:**属于RISC,新兴架构,最大优点是开源,常用于云计算、物联网等
- memory hierarchy
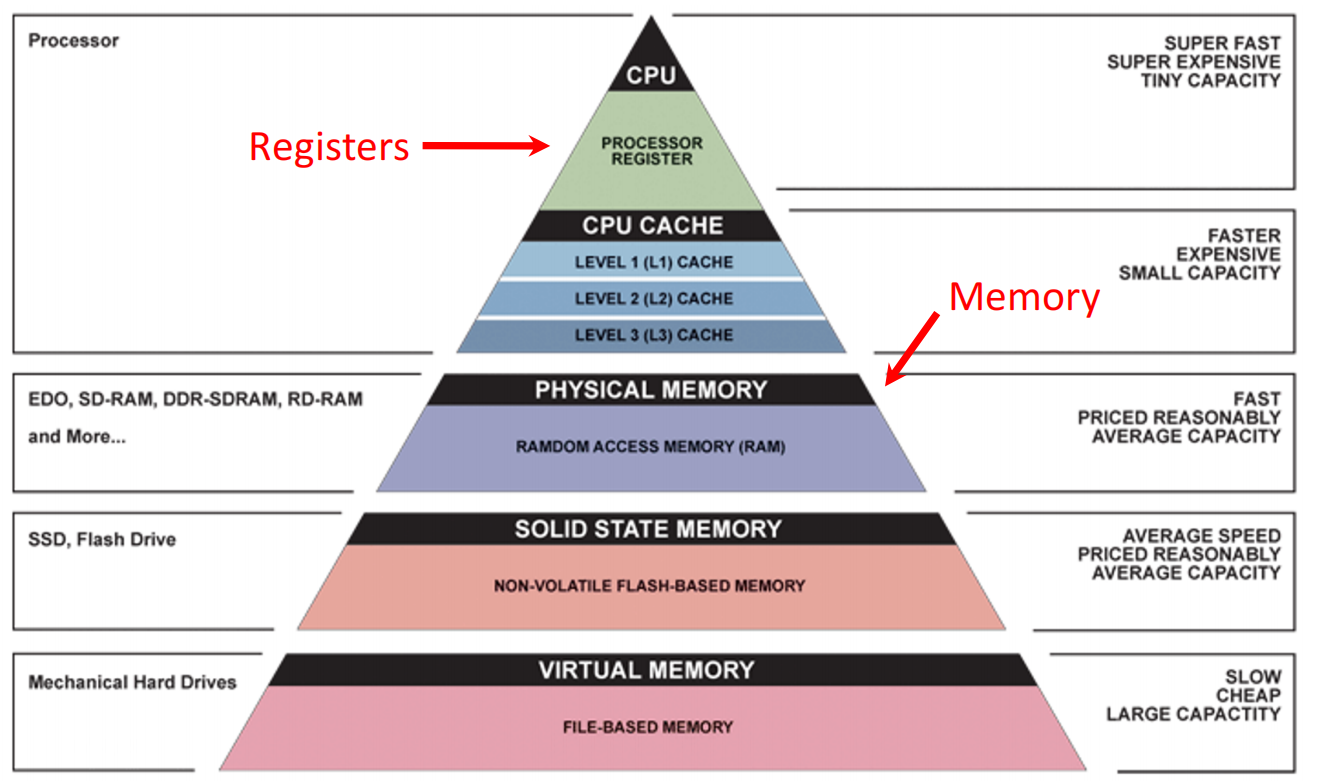
-
riscv简介
共32个寄存器,有些用于存编程中的变量,有些用于存临时变量

基本语法:

数据传输指令:
- Load Word(lw):读内存,即memory 到register
- Store Word(sw):反之

内存读写指令:
- lb:lb rd,imm(rs) —— 从内存 imm+rs 处读取8bit数据(符号拓展)到 rd 中
- sb:sb rs2,imm(rs1) —— 将rs2中的8bit数据写入内存imm+rs1处
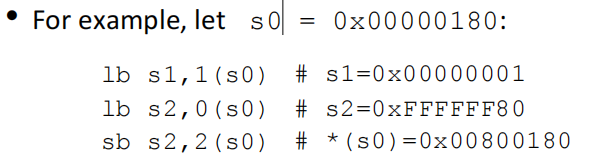
💡 PS.
- riscv采用的是小字节序,即对于s0,第一个字节存80,第二个存01这样子
- offset的单位是字节
- 因为lb只读写8个bit,而riscv是32位架构,所以要进行符号拓展。如给s2中读入0x80,即1000 0000,拓展后s2的前24位就都变成了F
- 也有其它的读写指令,如lw和sw是读写32bit数据
控制指令:

- beq:相等则跳
- bne:not equal
- blt:branch less than
- bge:branch greater than
- jal(jump and link):jal rd,label指令的下一条指令地址存入rd,跳转到label
比较指令:

Lecture7、RISC-V Functions
-
位数拓展
拓展符号位即可,即正数补充0,负数补充1

-
函数

其中jal的参数ra是x1寄存器,存放函数返回地址(return address)
而伪指令j等效于jal x0 label,由于x0恒为0且无法更改,所以相当于只跳转而不记录返回地址;
jr等效于jalr x0,0(rs),(rs+imm)位置的内存到x0(实际无效),并跳转到rs寄存器保存的地址
💡 PS. jal和j都是用label跳转;jr是用寄存器跳转
Lecture8、RISC-V Instruction Formats
-
汇编代码转换为二进制代码:
思路:将一条汇编语句分为各个field,每个field占据一定的位长,表示特定含义(一条汇编语句占据32bit)
如R-Format语句:输入3个寄存器(add、mul等)
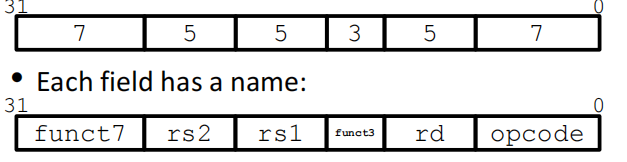
寄存器的field都是5bit,正好可以表示32个寄存器
Lecture10、digital logic
- 布尔代数运算
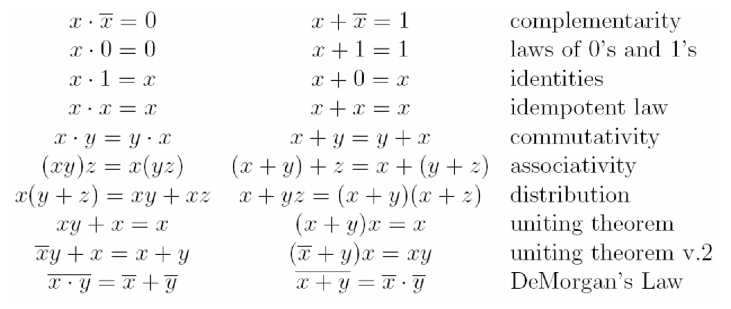
- 数电系统有两种基本类型:
-
**combinational logic(CL):**输出仅仅是输入的函数,与历史状态无关(如cpu中的加法运算器)
-
**sequential logic(SL):**与历史状态有关(如memory and registers)
Lecture12、RISC-V Datapath, Single-Cycle Control Intro
-
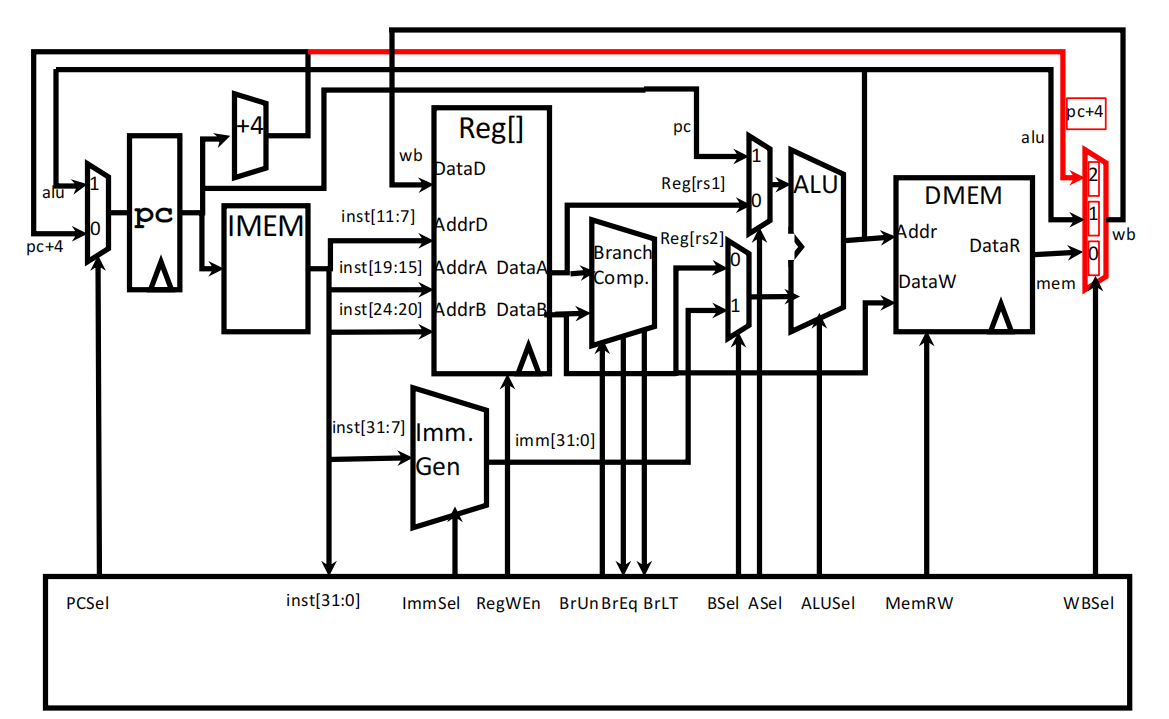
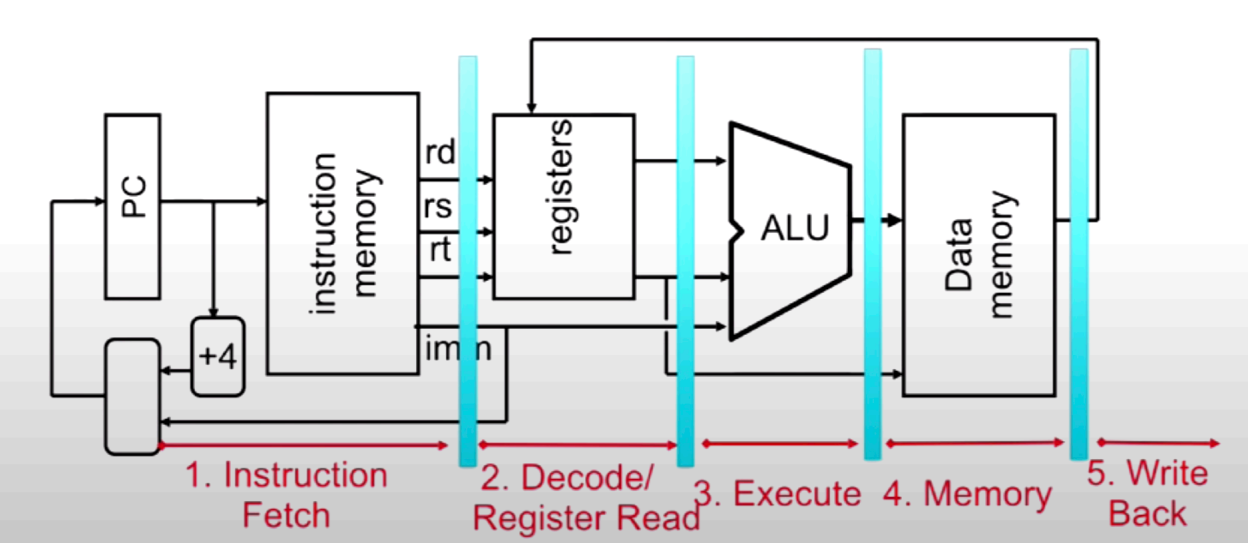
cpu执行汇编语句的硬件实现
**版本1.0:**实现R-type语句(以add t0 t2 t3为例)
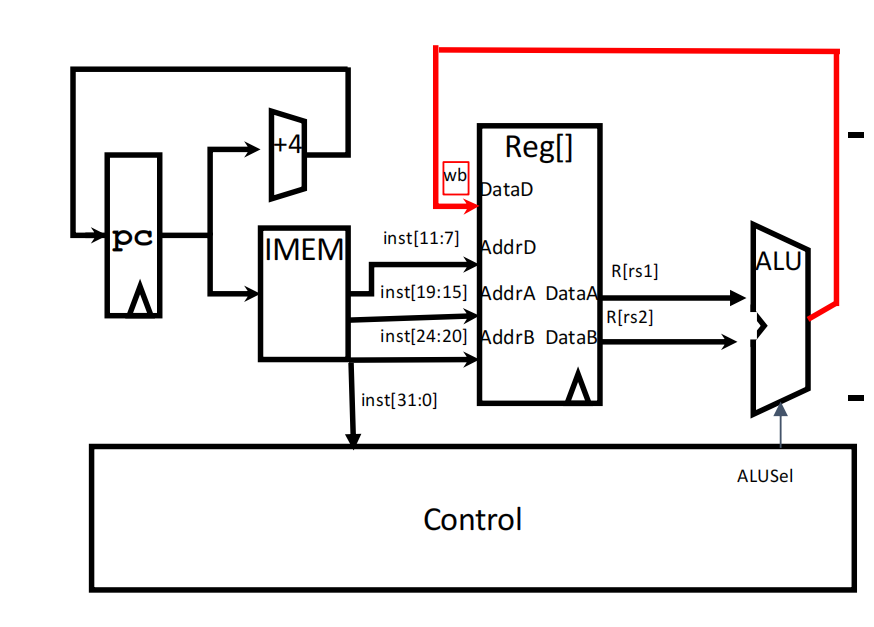
(1) 获取汇编指令:在PC寄存器中获取当前指令的地址,将指令内容传给IMEM(instruction memory),同时加4byte返回给PC(即下一条指令的地址)
(2) 将指令分段成各个field
(3) 将寄存器地址传给寄存器堆(register file),获取寄存器中的值
(4) 将获取的值传给运算器ALU,并由控制位ALUSel(ect)决定采用哪种运算(add、sub、xor。。)
(5) ALU输出运算结果并将值return给register files
**版本2.0:**实现loads类型语句(lb、sb)
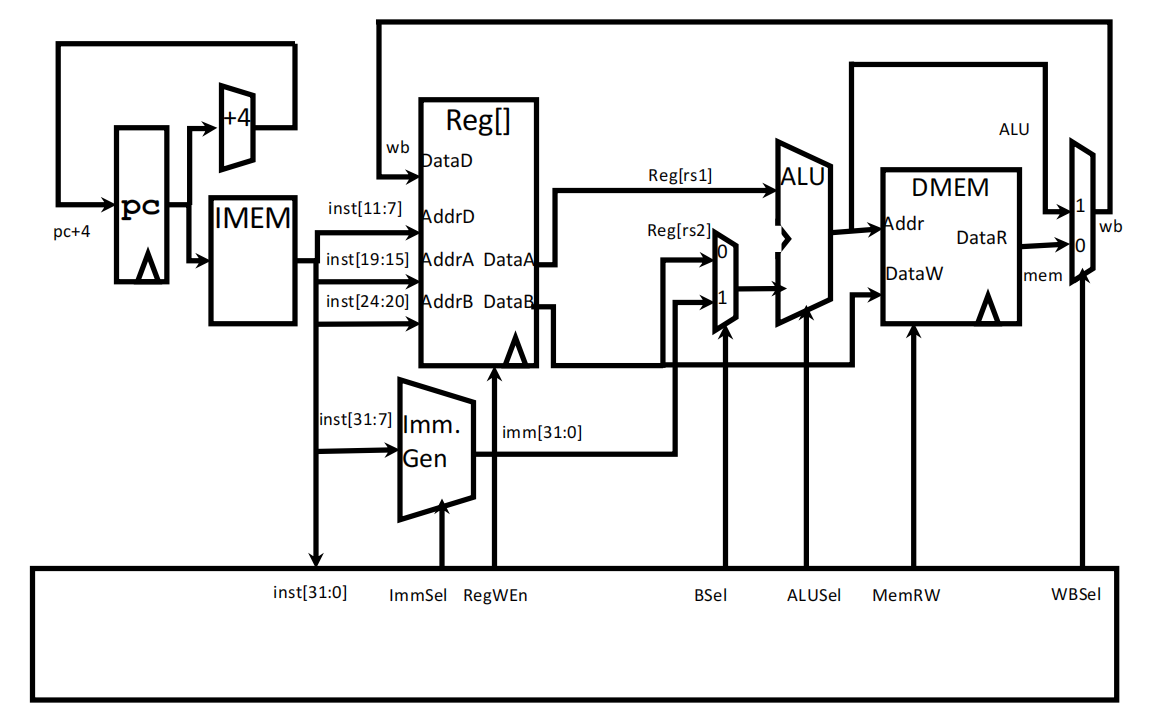
说明:
(1)多了一个immediate generator,用于生成立即数,再在01选择器处进行选择,即add和addi的区别
(2)多了一个data memory,用于执行loads类型的指令(在内存中读写数据),其中MemRW(memory read and write)用于选择读/写:为0时读数据,将Addr处的数据输出;为1时写数据,将输入的数据存到Addr处的内存中
**版本3.0:**实现分支控制语句(beq、blt)
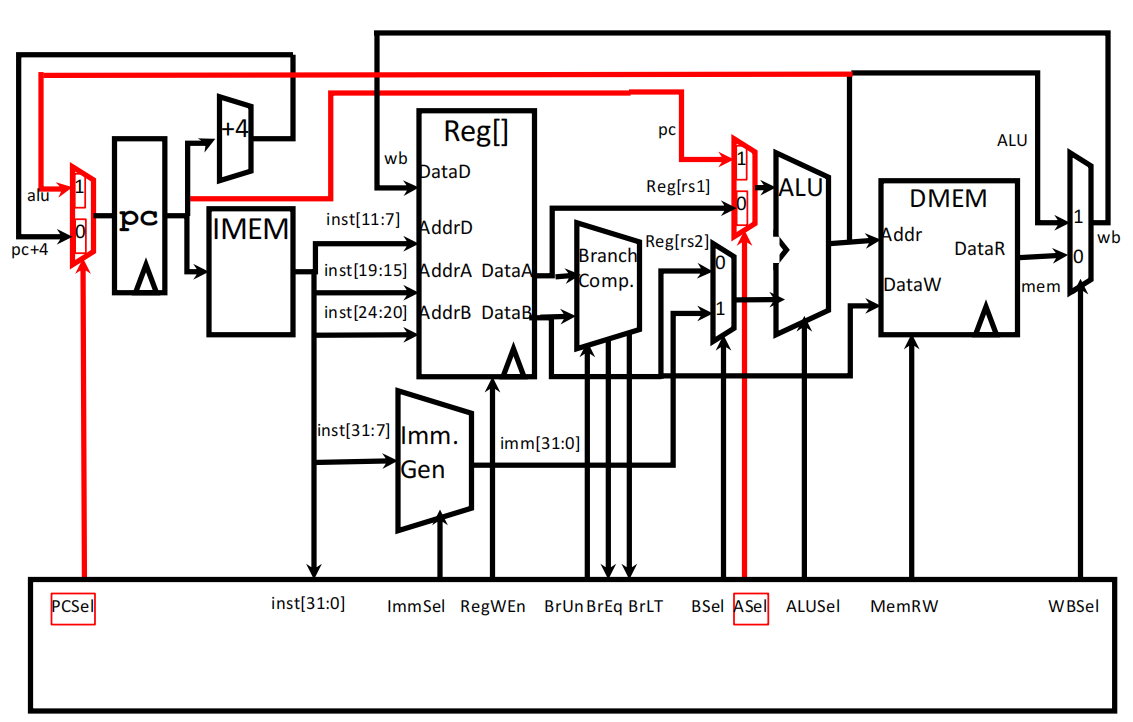
说明:多了分支控制模块,将DataA和DataB进行比较,根据结果将下面BrUn几个控制位设为0/1,再用ASel控制01选择器,使ALU的输出为要跳转的地址,return给PC
**最终版本:**实现跳转语句
Lecture13、RISC-V Single-Cycle Control and Pipelining
-
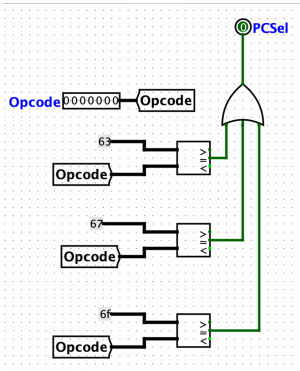
控制器设计
以PCSel为例,默认输出0,仅当opcode为branch语句(63)或jump语句(67或6f)时才会输出1,则在mux中选择ALU输出
-
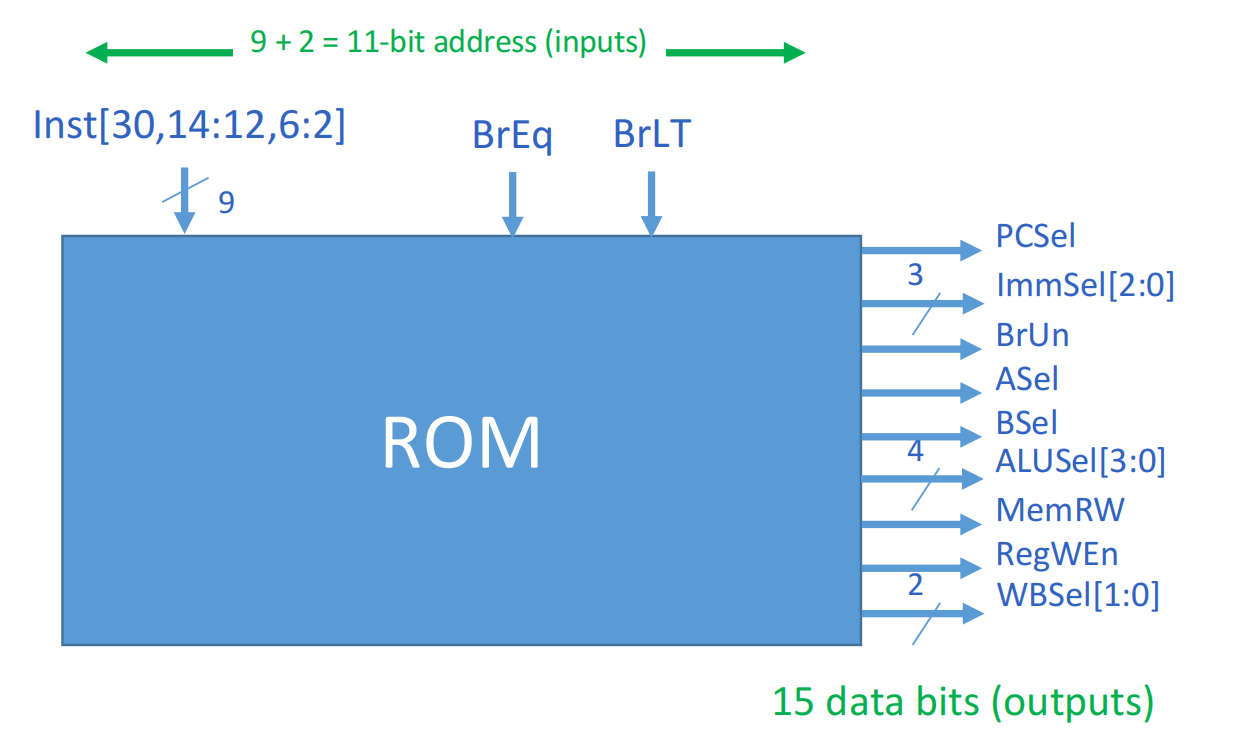
控制器结构
观察上面的CPU结构可知,控制器一共有三个输入,其余的皆是输出
实际中由ROM实现控制器
-
pipeline
**motivation:**单条指令运行时,大部分版块都处于空闲状态,

cpu性能表现:

(1)每个程序的指令数取决于:
- 程序算法的时间复杂度
- 编程语言
- 编译器
- ISA
(2)每条指令要执行多少个cpu循环
- 指令复杂程度
(3)每个cpu循环所耗费的时间
- cpu设计
- 电子参数(晶体管尺寸、电压大小)
流水线技术:
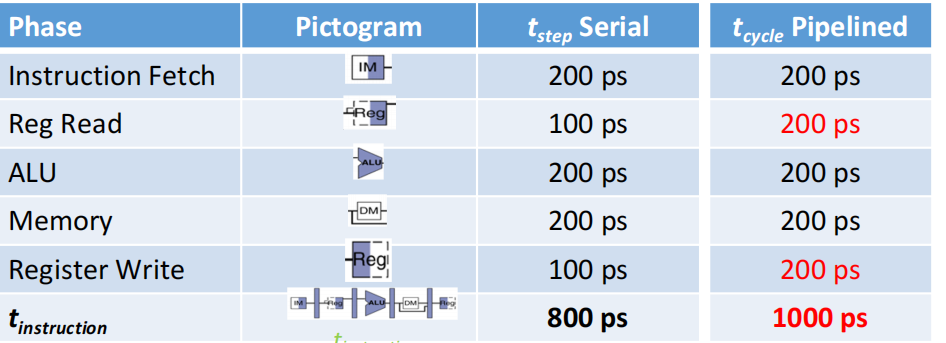
💡 PS. 流水线中,单个板块的耗时由短板决定
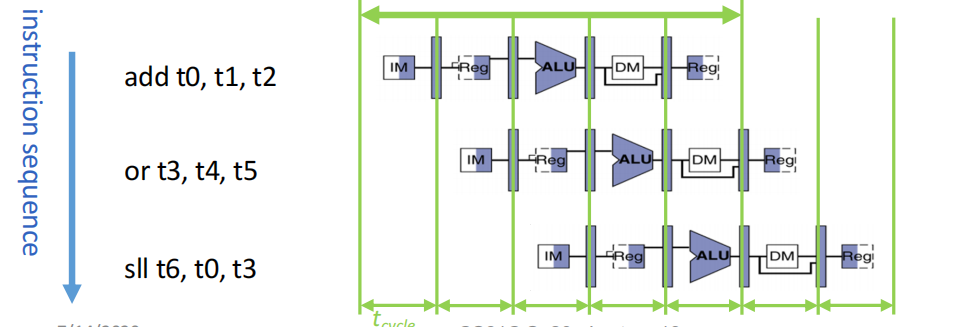
riscv的5段流水线
Lecture14、RISC-V 5-Stage Pipeline
-
流水线设计也会带来一些问题:
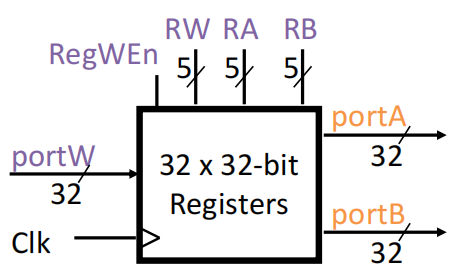
**结构性问题:**抢占资源,如两条指令同时需要用到RegFile
解决思路:
- 让读/写端口相互独立
- 在一个时钟周期的前半部分写数据,后半部分读数据(这在理论上是可行的,因为RegFile的access time远低于时钟周期的一半)
**数据更新问题:**一个典型案例,多条语句都要对t0进行修改,但第一次还没生效,后面几次就开始用了
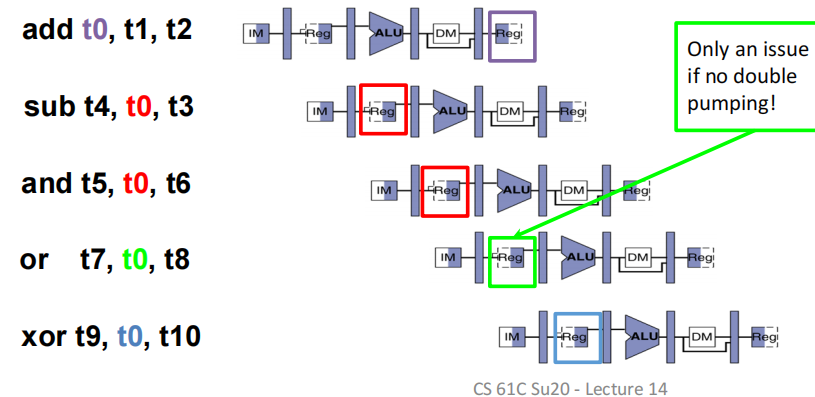
解决思路:
- 贮存:加入一些空指令进行拖延,确保上一条指令的结果写入后,下一条指令才开始读取
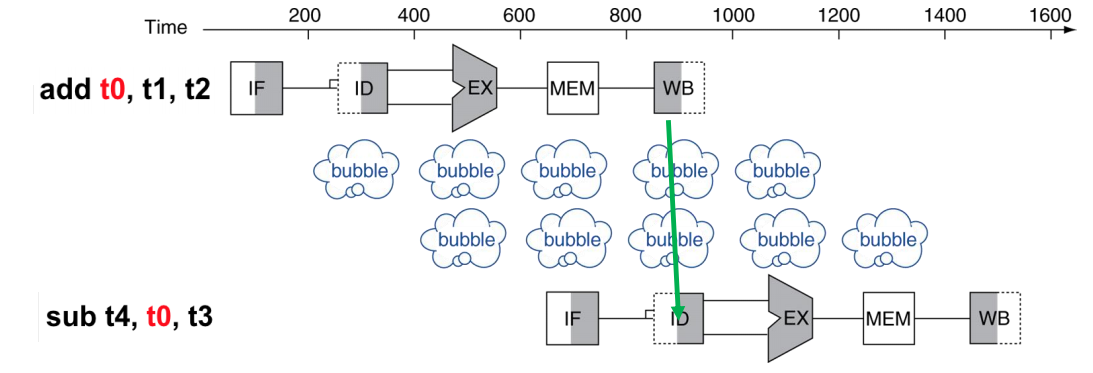
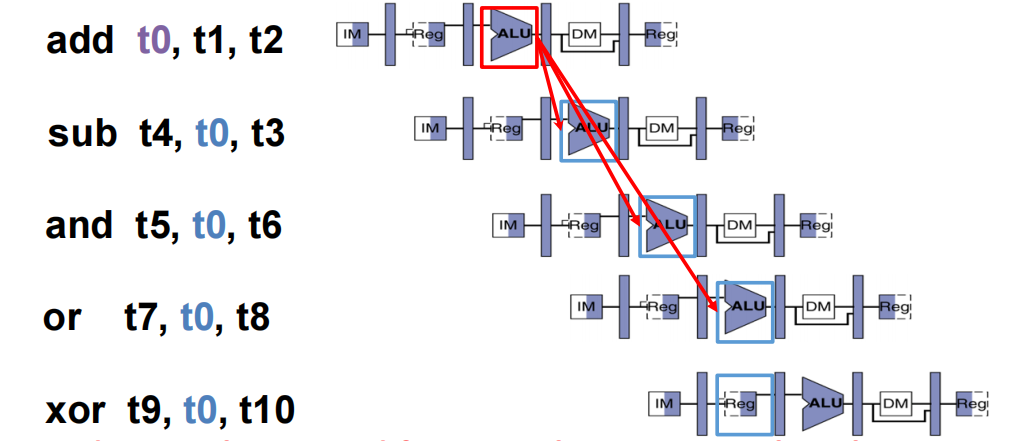
- 转发:结果算出后立马传输给之后的ALU,而不是从RegFile中读取
分支控制问题:”等待branch语句产生结果“这一行为会带来巨大的延迟,如所谓的流水线打嗝(pipeline hiccup)产生气泡(bubble),为此我们可以使用**分支预测(branch prediction)**来解决这个问题。
先来看一段代码,在一个大小为32768的数组中随机、均匀地放入0~255的数字,再去统计数组中>128的数的总和
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35#include <algorithm>
#include <ctime>
#include <iostream>
int main()
{
// 随机产生整数,用分区函数填充,以避免出现分桶不均
const unsigned arraySize = 32768;
int data[arraySize];
for (unsigned c = 0; c < arraySize; ++c)
data[c] = std::rand() % 256;
// !!! 排序后下面的Loop运行将更快
std::sort(data, data + arraySize);
// 测试部分
clock_t start = clock();
long long sum = 0;
for (unsigned i = 0; i < 100000; ++i)
{
// 主要计算部分,选一半元素参与计算
for (unsigned c = 0; c < arraySize; ++c)
{
if (data[c] >= 128)
sum += data[c];
}
}
double elapsedTime = static_cast<double>(clock() - start) / CLOCKS_PER_SEC;
std::cout << elapsedTime << std::endl;
std::cout << "sum = " << sum << std::endl;
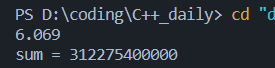
}对于有序数组:
而对于无序数组:
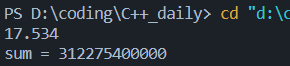
上述耗时差异由分支预测导致,而实际中的分支预测常由历史数据决定。对于有序数据,前一半皆<128,处理器很容易找出其中的pattern;无序数组则相当于瞎蒙,只有50%的命中率
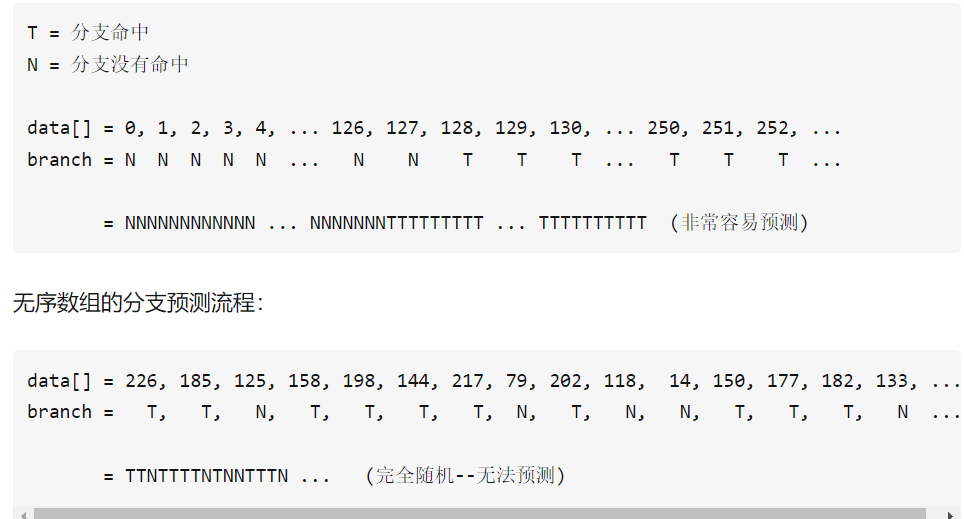
💡 PS. 这个例子给我们启示: 在大规模循环逻辑中要尽量避免数据强依赖的分支(data-dependent branching).
分支预测的策略大致可以分为两种:静态预测和动态预测
**静态预测:**固定的预测策略,如”≥指令一律跳,<一律不跳“、”与上次taken保持一致“,这类策略简单易实现且能耗小,也可以保持不错的正确率(70%以上),对性能要求不是特别高但又要低功耗低成本的系统可以使用
**动态预测:**如2-bit 状态机: 初始值为00,每当一个branch taken就+1,branch没有taken则-1。根据第一位的值来进行预测,例如11预测taken,01预测 not taken。 用一个2bit状态机的核心思路就是:这次预测错了不要紧,再给你一次机会,还是预测错了的话那再改变预测结果。总之就是提供了一定的容错率,可想而知这样的预测准确率自然也是提高了的。
Lecture15-17、 Cache
- 典型内存分级
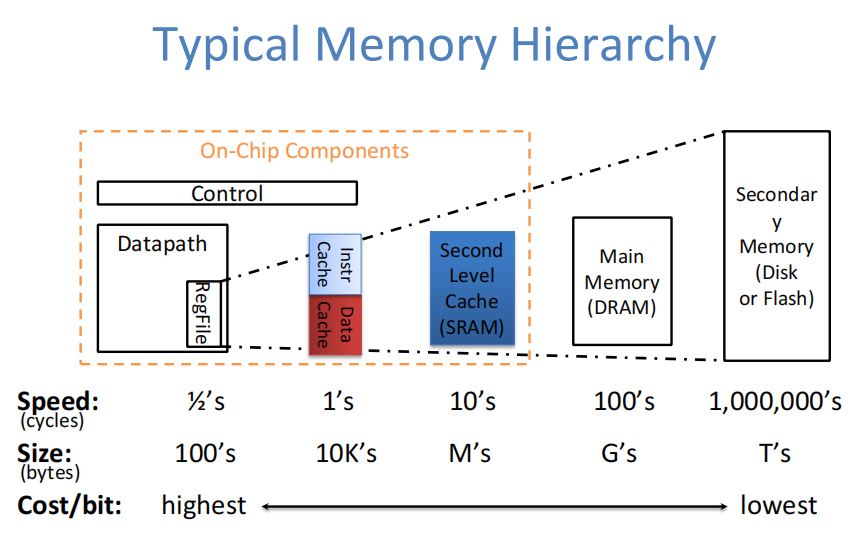
cache用static RAM:更快(1ns),但功耗更高也更贵,通电时内容一直在
主存用dynamic RAM:更便宜也更慢(70ns),定时更新内容
-
**两个基本原理:**时间局部性(如果一个地址被访问了一次,那么它接下来还可能被访问很多次)与空间局部性(如果一个地址被访问了一次,那么它周围的内存也可能被访问,如数组)
-
以直接映射(direct mapping)为例,完整叙述cache工作过程
假设cache大小64bytes,分为8个cache line(或称cache block),则每个line大小为8bytes
💡 PS. cache line是cache和主存之间传输数据的最小单位,line 大小一般设为word的整数倍(4byte、8byte这样子),很少会做成1byte,为什么捏?见下文分析
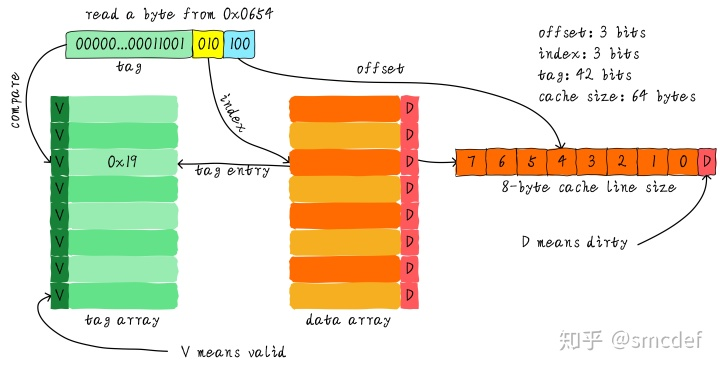
假设地址位宽为48bit,cpu现在要在地址为0x0654空间中读数据,那么如图,首先通过黄色部分的010(称之为index)找到对应位置的cache line(这个过程可以称之为一次hash),但光找到line还不够,因为如果两个不同地址的bit3-bit5一样的话,经过hash后都会找到同一个cache line。 下一步是比较绿色的tag——每一个cache line都对应唯一一个tag,tag中保存的是整个48bit地址除去index和offset后的剩余部分。若地址的tag和line对应的tag相等,则说明cache确实把内存中前45位地址为00….011001010xxx的那8byte空间全搞进来了,即cache hit。ok,那么接下来只需要通过蓝色的offset就可在line中找到具体的那个byte;若tag不相等,则cache miss。这也解答了我们之前的一个疑问“为啥cache line不做成一个byte”,因为原本8byte对应一个tag,现在需要8个tag,占用太多空间(tag也是cache的一部分,但我们谈到cache size的时候并不考虑tag占用的内存部分)。 图中还可以看到tag旁的valid bit,它用来表示cache line中的数据是否有效,如系统刚启动时,cache中的数据应该都是无效的,因为还没有缓存任何数据。所以实际中比较tag前还会检查valid bit是否有效,无效则直接判定cache miss。
💡 PS. 体会一下上述查找cache的过程,会发现虽然看起来有点复杂,但本质上就是个通过地址找对应数据的过程——先判断cache中是否有这前45位地址,有的话直接往后找我要的那个数据,没有的话cache miss
直接映射优点:硬件设计简单、成本低 缺点:程序依次访问0x00、0x40、0x80(这3个地址的index一样的)时,首先访问第0个line,再访问0x40地址时依然会检索到第0个,然后发现数据缺失,于是从主存中加载0x0地址数据到第一个line,0x80亦是如此,所以此时cache的存在并没有对性能有啥提升,这种连续加载替换cache的现象叫做cache颠簸(cache thrashing),针对这个问题我们引入多路组相连缓存
-
两路相连缓存(two-way set associative cache)
依然假设64 Bytes cache size,cache line size是8 Bytes。两路组相连缓存就是将cache平均分成2份,每份32 Bytes。
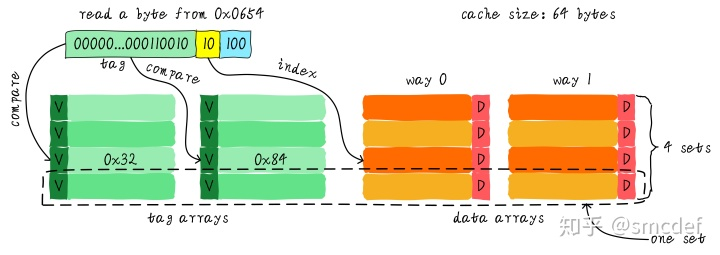
cache被分成2路,每路包含4行cache line。我们将所有index一样的cache line组合在一起称之为一个set。例如,上图中一个组有两个cache line,总共4个组。我们依然假设从地址0x0654地址读取一个字节数据。由于cache line size是8 Bytes,因此offset需要3 bits,这和之前直接映射缓存一样;不一样的地方是index,在两路组相连缓存中,index只需要2 bits,因为一路只有4行cache line。上面的例子根据index找到第2行cache line(从0开始计算),第2行对应2个cache line,分别对应way 0和way 1。因此index也可以称作set index(组索引)。先根据index找到set,然后将组内的所有cache line对应的tag取出来和地址中的tag部分对比,如果其中一个相等就意味着命中。 因此,两路组相连缓存较直接映射缓存最大的差异就是:第一个地址对应的数据可以对应2个cache line,而直接映射缓存一个地址只对应一个cache line
-
全相连缓存(Full associative cache)
进一步把所有的cache line放在一个组里,称之为全相连缓存
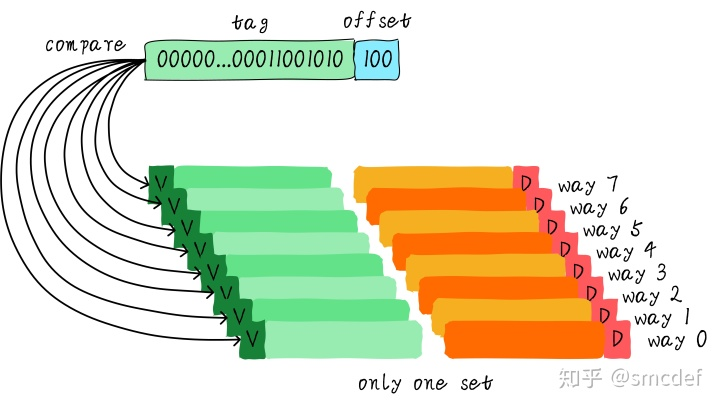
由于所有的cache line都在一个组内,因此地址中不需要set index部分。因为,只有一个组让你选择,也就是没得选。我们根据地址中的tag部分和所有的cache line对应的tag进行比较(硬件上可能并行比较也可能串行比较)。哪个tag比较相等,就意味着命中某个cache line。因此,在全相连缓存中,任意地址的数据可以缓存在任意的cache line中。所以,这可以最大程度的降低cache颠簸的频率,但是硬件成本上也是更高。
-
缓存命中
cache hit:cache中有block的有效副本,所以能返回期望数据
cache miss:cache中没有想要的block,所以只能从memory中取出
block replacement:若cache满了,就要撤销其中一个block,用期待读取的数据替换。但是替换哪个block捏?
常用的cache算法:
-
随机替换
-
Least Recently Used(LRU):最近一次访问时间最久远的那个block
-
-
多级cache之间的配合工作:
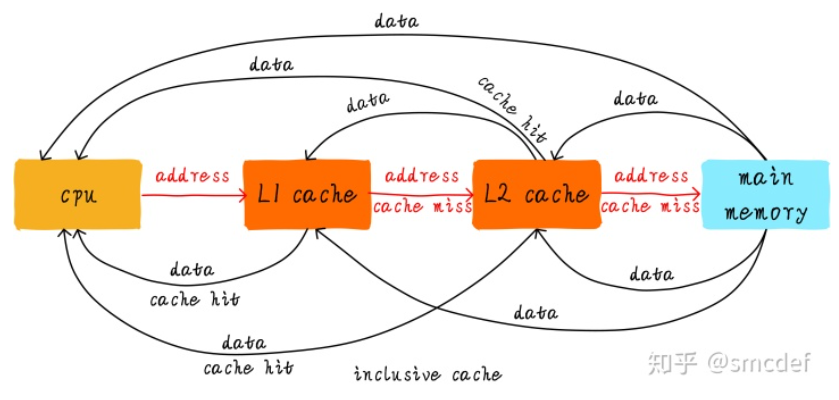
当CPU试图从某地址load数据时,首先从L1 cache中查询是否命中,如果命中则把数据返回给CPU。如果L1 cache缺失,则继续从L2 cache中查找。当L2 cache命中时,数据会返回给L1 cache及CPU。如果L2 cache也缺失,很不幸,我们需要从主存中load数据,将数据返回给L2 cache、L1 cache及CPU。这种多级cache的工作方式称之为inclusive cache。某一地址的数据可能存在多级缓存中。与inclusive cache对应的是exclusive cache,这种cache保证某一地址的数据缓存只会存在于多级cache其中一级。也就是说,任意地址的数据不可能同时在L1和L2 cache中缓存
-
写操作:
写操作会造成cache和主存中的数据不一致,那么如何保证数据操作正确捏?
-
通写(write through):把数据写入cache的同时也写入主存,好处是保持一致性,坏处是极其影响写速度
-
回写(write back):先把数据写回cache,当cache中的数据被替换时再写回主存。具体通过dirty bit实现,数据修改则置位。

-
-
AMAT(Average Memory Access Time)
同时考虑命中和丢失时的获取memory中数据的平均时间


AMAT=1+0.02*50=2 clock cycles=400ps
——190ps clock:2 cycles=2*190=380
——MP of 40 clock cycles:1+0.02*40=360
——MR of 0.015*50=350 (√)
Lecture18-19、Operating Systems & Virtual Memory
-
OS的最典型特征之一就是多任务,依赖于不同处理器的进程切换,但这个过程可能导致内存资源地址等发生变化
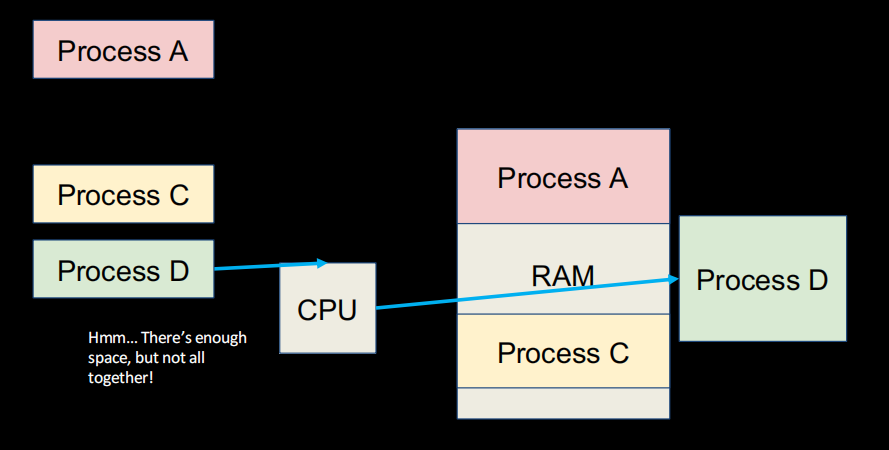
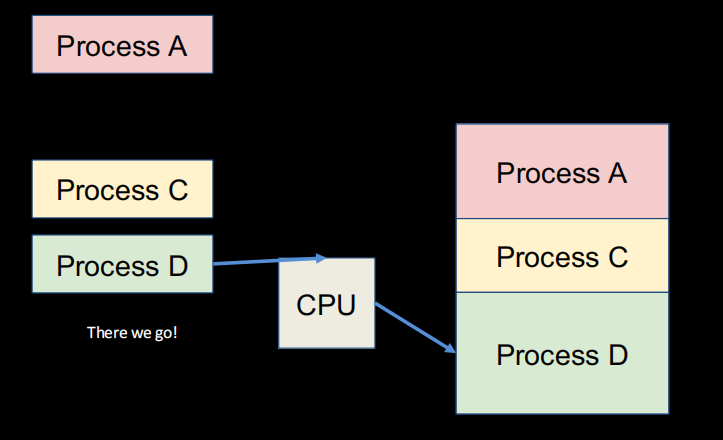
造成这种现象的原因是应用未完全隔离,一个应用可以覆写另一个应用的内存,同时考虑到一些其他问题(如可能会处理比我们真正需求要多不少的内存,像稀疏矩阵),我们引入虚拟内存
-
virtual memory
- 虚拟内存VM:给每个进程隔离的空间,进程认为其内存足够大,并且完全属于自己(仅自己有访问权)
- 物理内存PM:电脑中真实的限制性的RAM
key idea:由于程序大小的膨胀,且系统同时运行多个程序,经常会出现需要空间>实际内存的问题,而虚拟内存可有效解决该问题:每个进程都持有各自的虚拟内存,分为很多个页,但并不是所有页都必须在内存中时才能运行程序。用到哪一页,就作映射去物理地址寻找数据;若映射这个物理地址不在内存中怎么办捏?那它在哪里捏?答案是:外存,即disk。接下来由系统自动完成将外存调入内存的的工作;而当内存空间不够时,系统按一定算法释放某部分内存空间。 通过上述操作,就能让程序在运行中感觉到拥有一个不受内存容量约束的、虚拟的、能够满足自己需求的存储器。
主要需要达成的几个目标:
-
进程隔离
-
有限到无限空间的过渡
-
VM、PM地址的转换
-
解决思路:分段内存(segmented memory)
每个段用基地址(base)和偏移地址(bound)表示,每个程序独享一个segment,在各自的内存视角中,都认为自己这个段的段首地址是0x0000
在裸的五段流水线中,PC输出的是真实的物理地址;但在base and bound机制中:
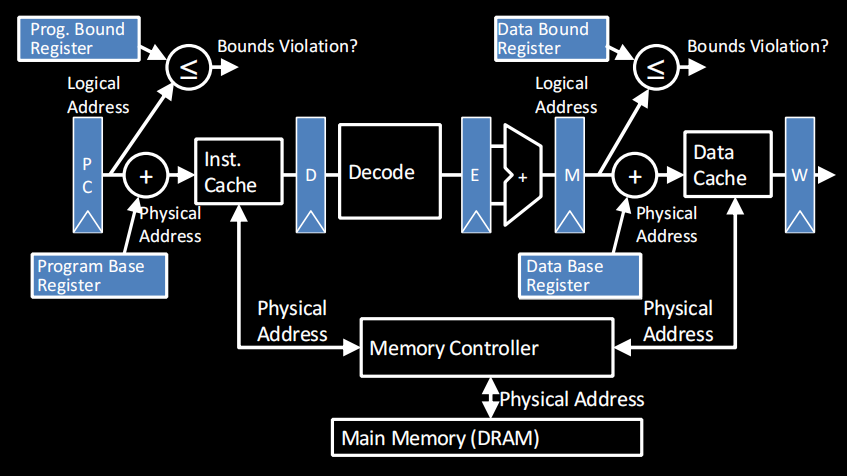
但分段内存仍有一些问题:如果我们需要的地址比段空间大捏?RAM都分成了段导致连续空间不够捏?
-
分页内存(paged memory)
**key idea:**把物理内存均分为多个page,每个进程可以独享多个page。page在RAM中不必真的连续,但在各个进程的视角看来,它们对自己来说就是连续的
那VM、PM地址如何转换呢——page table,每个进程维护一张,用于记录自己占用的page和其真实物理地址
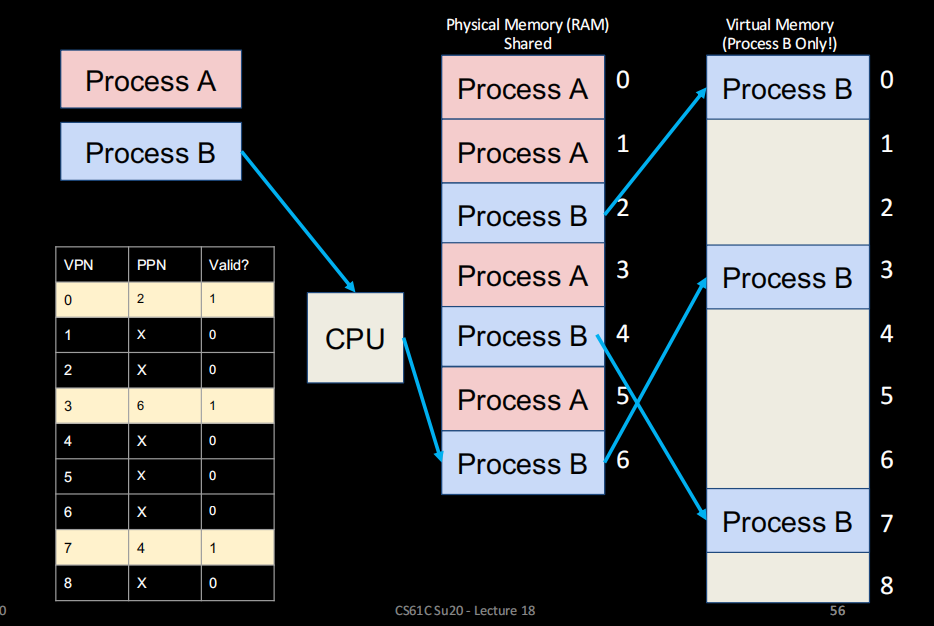
注意:虚拟内存在RAM没有对应是一件很正常的事哈(图中黄色的那些页),C盘里那个巨大的PageFile.Sys就是放在外存里的虚拟内存
-
地址转换

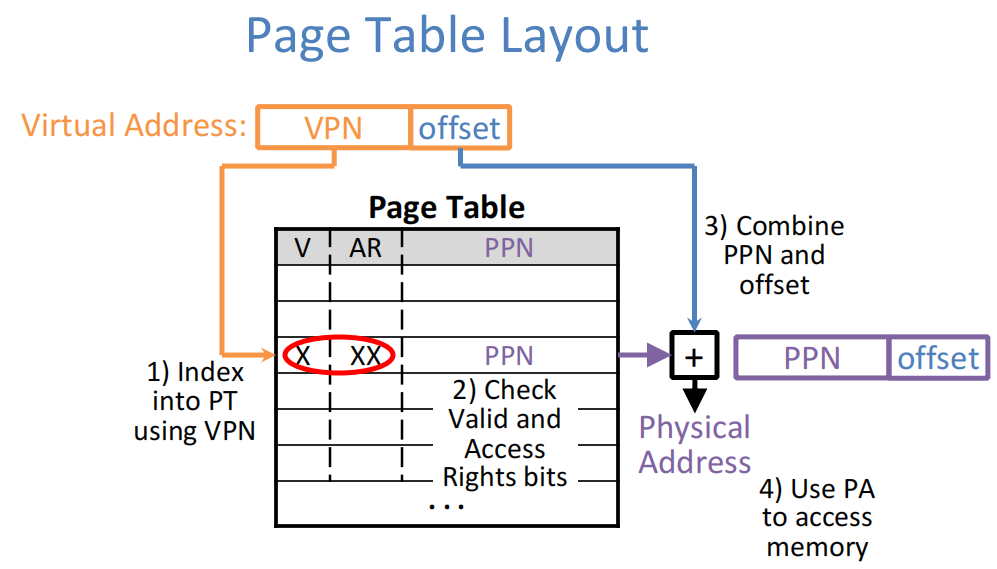
转换算法:
1)通过virtual page number在表中找到对应位置
2)检查valid和access rights位是否有效
3)通过physical page number和offset算出物理地址
-
页面表
若是简单的线性结构表,需要表0和表n时得遍历整个表,很耗时间(一个操作系统中page table里的entry可多达数百万条),为此,我们可以使用一些改进结构
-
分级分页
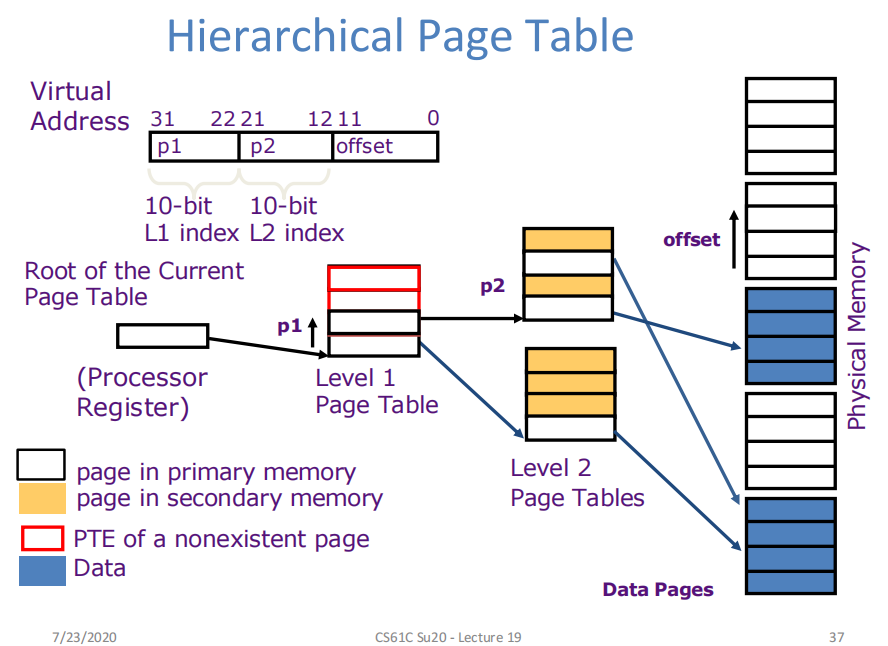
-
-
页表缓冲TLB(Translation Lookaside Buffer)
在分级分页中,获取一个数据可能需要多次访问physical address,造成速度缓慢,而既然page中也存在局部性,那我们可以考虑使用和cache的类似的缓存结构
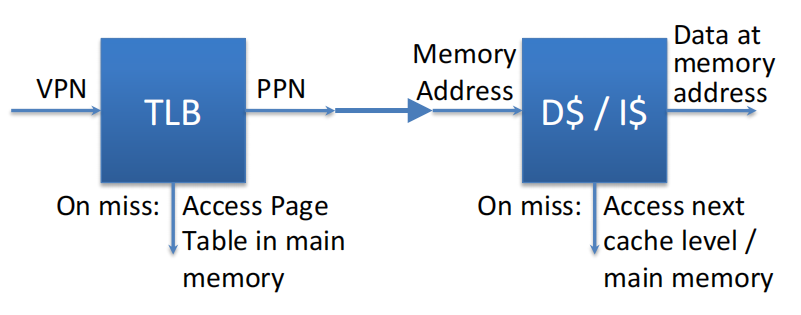
- TLB中存的不是内存数据,而是VPN→PPN的映射
- TLB通常很小,一般存32-128条entry
- 速度比cache快很多
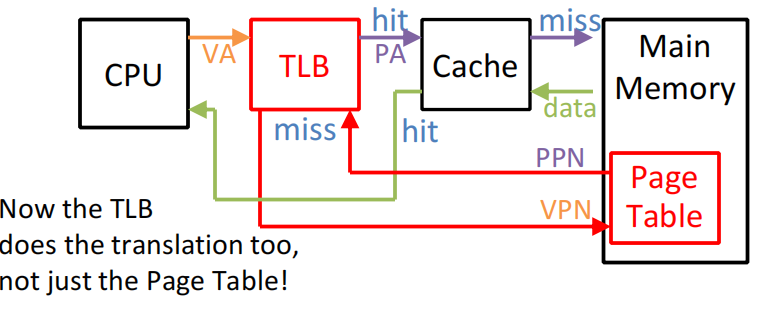
**TLB和cache的组合工作原理:**先在TLB中查虚拟地址,命中则直接在cache中读物理地址;否则在page table中找映射关系
Lecture20、IO
-
**disks are I/O:**因为cpu无法从磁盘(包括ssd和机械)中直接读写数据,page从disk移向RAM后才会变成memory;电脑没disk也能跑
-
IO操作方式:
处理器频率一般远大于IO设备,所以需要一定方式进行操作
-
轮询(polling)
处理器在循环中不断等待control register信号,若ready bit置一,则处理器向data register中读写数据,c语言中的while(getchar()==‘x’)其实就是一种最简单的轮询思想 轮询对于一些简单设备没问题,如鼠标,一秒只做30次polling,cpu耗时比例很低;但磁盘每秒读写数MB的数据,算下来cpu高达40%的时间都耗在轮询上,显然不可接受
-
中断(interrupt)
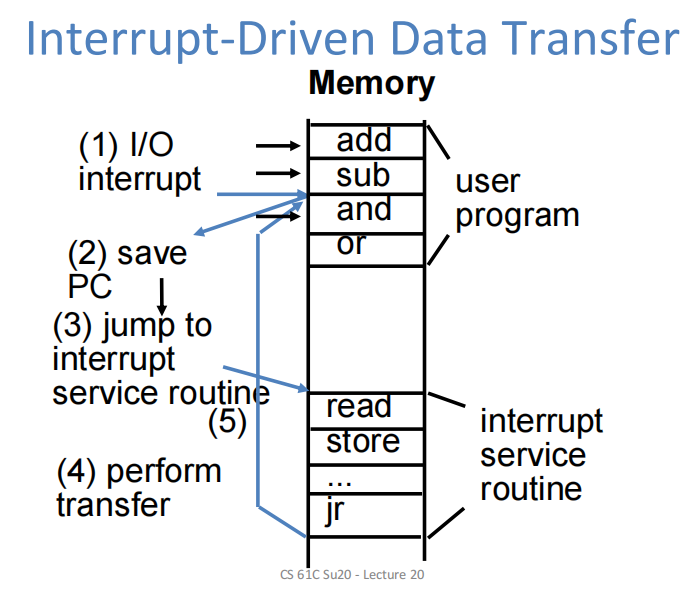
经计算,中断可把cpu在磁盘读写上的耗时降到2%,但还可以优化
-
**DMA:**memory和IO设备直接传数据,不经过cpu
一个比喻:polling像饿了去餐馆,过一会儿问下“菜好没”;interrupt像在线下单,你继续干活,做好了再叫你,去了直接拿直接走;dma则像下一单外卖,拿取都取消,只管等东西来
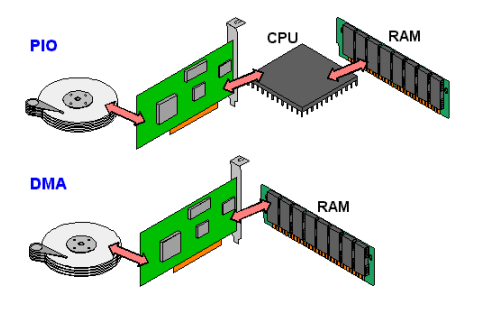
经计算,dma可把cpu在磁盘读写上的耗时降到0.2%
-
Lecture21、Data-level Parallelism
-
**motivation:**晶体管的发展受限,无法通过提高时钟频率进一步提升cpu性能,而并行正是解决这一问题的好方法
-
并行化分类
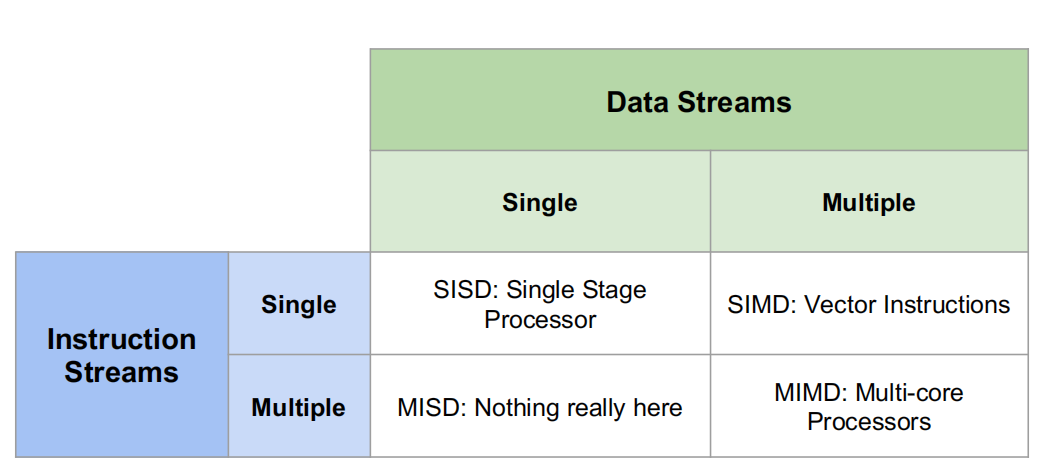
-
SIMD(Single Instruction Multiple Data)架构
许多基本数据类型为8bit,而现在处理器是32/64bit,若一次只用64位中的低八位处理数据显然很浪费,但若将64位寄存器拆成8个8位寄存器就能同时完成8个操作,计算效率提升8倍,这就是SIMD的初衷,具体表现为向量运算
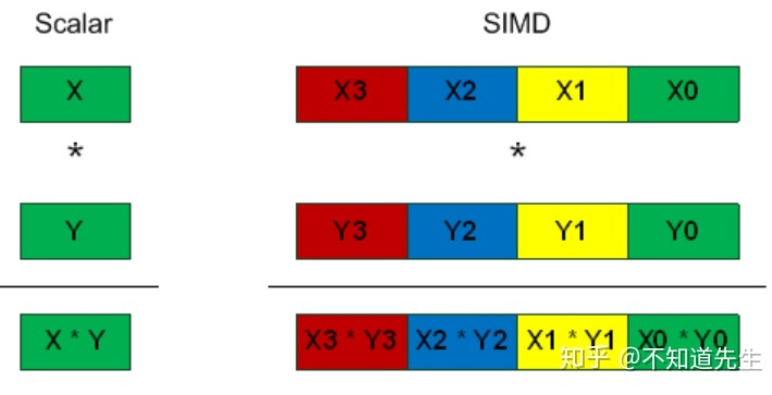
intel的一些拓展指令集SSE(Streaming SIMD Extensions)、AVX(Advanced Vector Extensions)用于进行SIMD运算
具体实现上,常用内置函数(intrinsics)方式,如下图所示让两数组相加
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18int add_no_SSE(int size, int *first_array, int *second_array) {
for (int i = 0; i < size; ++i) {
first_array[i] += second_array[i];
}
}
int add_SSE(int size, int *first_array, int *second_array) {
for (int i = 0; i + 4 <= size; i+=4) { // only works if (size%4) == 0
// load 128-bit chunks of each array
__m128i first_values = _mm_loadu_si128((__m128i*) &first_array[i]);
__m128i second_values = _mm_loadu_si128((__m128i*) &second_array[i]);
// add each pair of 32-bit integers in the 128-bit chunks
first_values = _mm_add_epi32(first_values, second_values);
// store 128-bit chunk to first array
_mm_storeu_si128((__m128i*) &first_array[i], first_values);
}
...
} -
循环展开

为什么这种循环展开可以加速运算呢?
未展开时的汇编代码:每个元素操作完后都要跳一次loop

展开后:汇编代码重排,可利用SIMD机制

Lecture22、Thread-level Parallelism
-
多处理器运行多进程(并行)
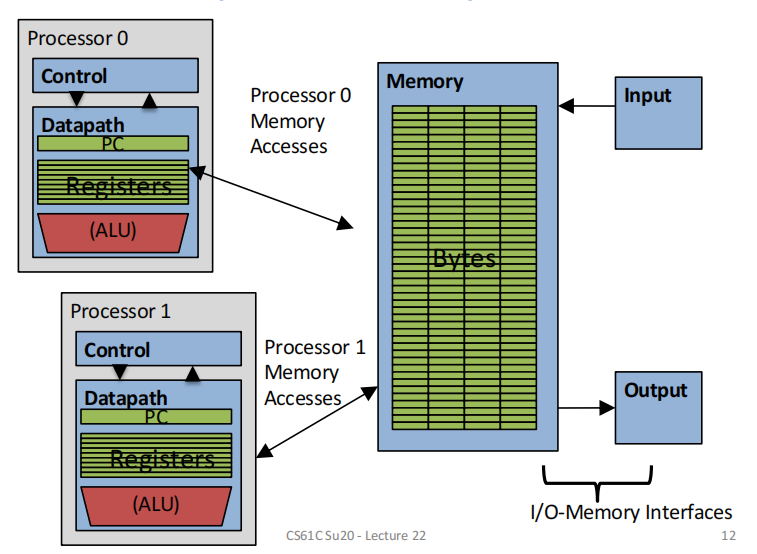
每个进程在各自的处理器上运行,但享用同样的系统内存
-
单处理器运行多个线程(并发)
各个线程有自己的PC、寄存器、栈空间,享用相同的静态空间。一个典型的例子是浏览器中开多个页面,每个页面的浏览器源码和全局设置是一样的,但有着各自不同的stack和寄存器(但事实上现在的浏览器出于安全和性能原因,给每个页面用的是独立的处理器)
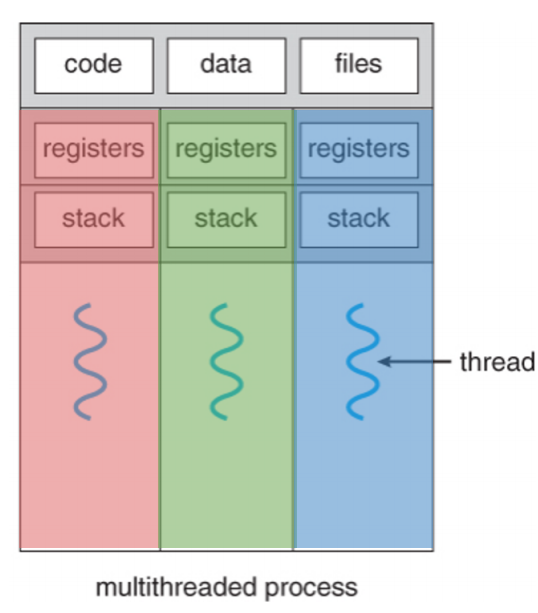
多线程有啥好处呢:处理器的资源宝贵,多线程可以尽可能**避免其空闲,**如cache miss后有个很长的memory latency,则直接切换到其它线程(所以切换上下文的开销得小于cache miss latency)
-
并发中的一些问题
-
加速性能
阿姆达尔定律:
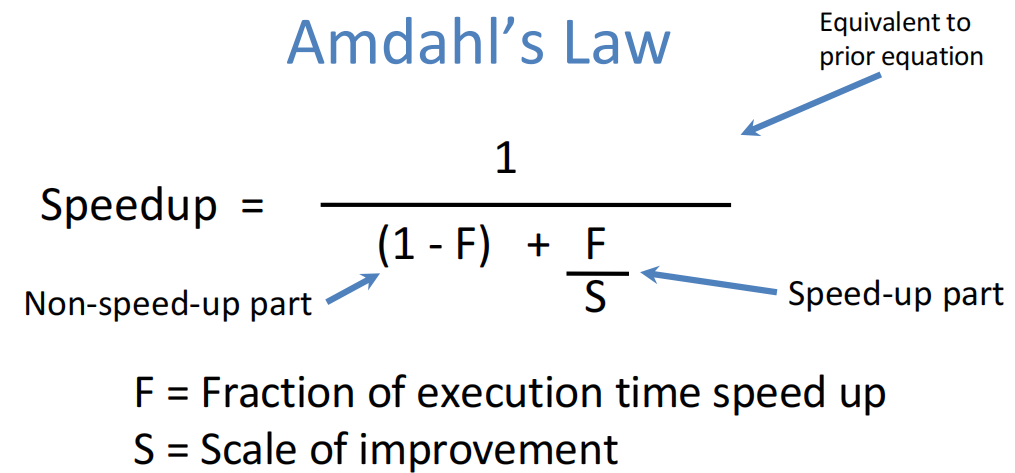
可知对于一个5%的时间使用并行,即使用5个处理器,其加速性能也不过是:

只有并行运算占比足够高时,处理器数量的增加才会带来明显性能提升
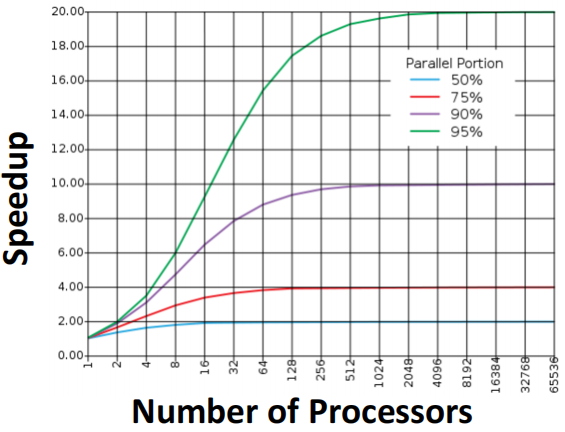
但这样的加速也有瓶颈,由阿姆达尔定律可知,S足够大时,speedup接近于常数
**解决思路:**原始运算中尽可能少用标量运算,也就是尽量提升并行化占比
-
数据竞争
线程调度是不确定的,因此当多个线程对同一个变量操作时,其最终的值也是不确定的
**解决思路:**不要往相同的内存写数据;让读写同步,从而获得确定行为
-
-
锁同步
用lock来对重要区域(比如有共同操作的变量的内存区域)作访问限制,以便一次只有一个线程能访问

-
cache coherence
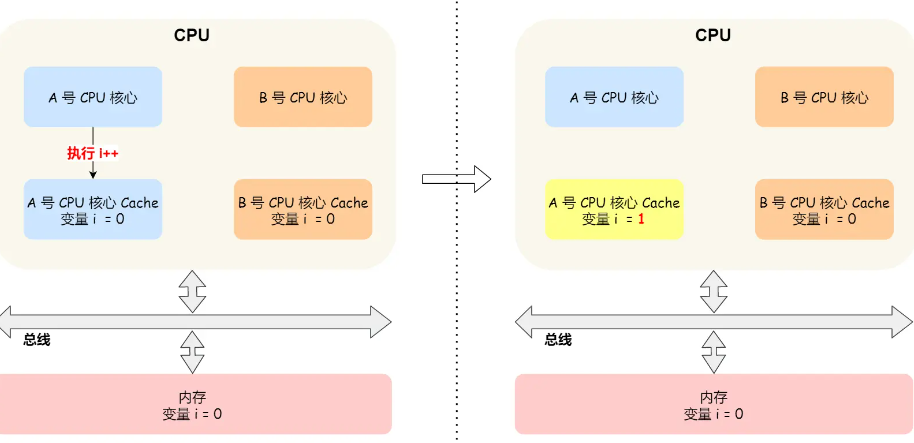
假设两个core同时运行两个线程,都对变量i进行操作,这时A执行了i++,cache采用写回策略,即先放到自己的cache里并把dirty bit置一,并未同步到memory。这时B从内存读i的值,则读到的将会是错误值,即所谓的缓存一致性问题
解决方法:
-
写传播(write propagation)
key idea:当某个core更新了cache中的数据时,要把该事件广播通知到其它core ,最常见的实现方法是总线嗅探(bus snooping)
如core A改变了i的值后,会通过总线把这个事件广播给其它所有core;其它core随时保持监听总线上的广播事件,并检查是否有相同的数据在自己的cache里,若有则更新
但这个方法并不完美:一来每修改一个数据都要广播一次,会加重总线负载;二来总线嗅探只能保证某个 CPU 核心的 Cache 更新数据这个事件能被其他 CPU 核心知道,但是并不能保证事务串行化(即不知道谁先改谁后改)
-
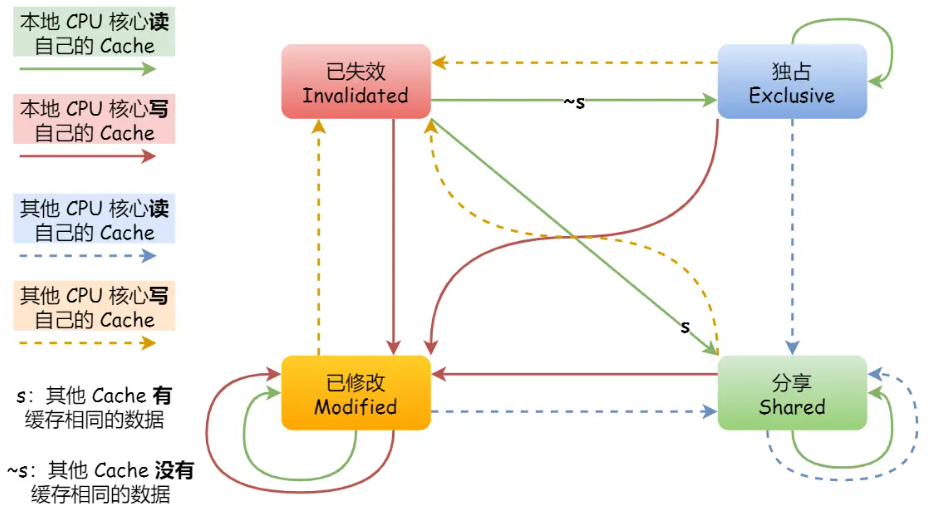
MESI 协议
MESI 协议其实是 4 个状态单词的开头字母缩写,分别是:Modified(已修改)、Exclusive(独占)、Shared(共享)、Invalidated(已失效),这四个状态来标记 Cache Line 四个不同的状态
整个 MESI 状态的变更,则是根据来自本地 CPU 核心的请求,或者来自其他 CPU 核心通过总线传输过来的请求,从而构成一个流动的状态机。另外,对于在「已修改」或者「独占」状态的 Cache Line,修改更新其数据不需要发送广播给其他 CPU 核心
-
Lecture24、Warehouse Scale Computers, MapReduce
-
典型结构
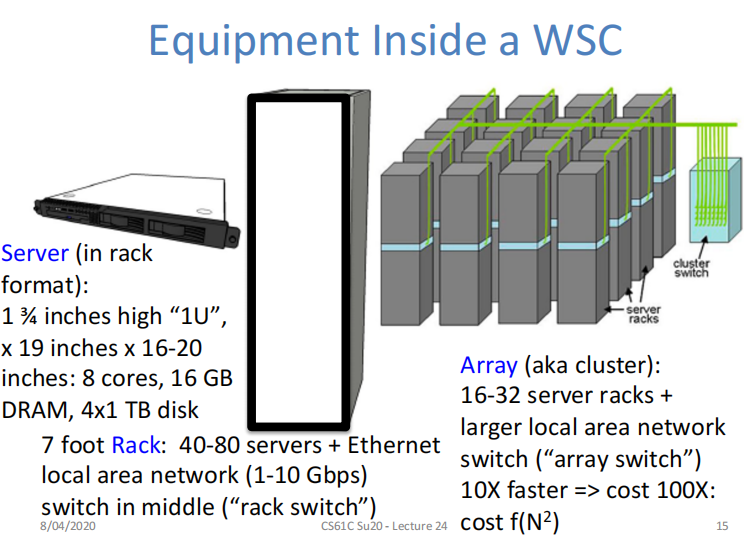
一个WSC中包含多个array(aka cluster),一个array中有多个rack(机架),一个rack中又包含多个服务器
-
阐述wsc架构工作过程(以google搜索hust为例)
- 发送请求给最近的Google warehouse scale computer
- 前端平衡负载,在众多cluster中找出最合适的那个
- 在cluster内部找出一个google web servers来处理请求,生成网页
- google web servers和内部服务器交流,找到包含“hust”的那个文件
- 返回相关的文件列表以及对应的关联分数
此外,随之发生的还可能有:
- 推荐系统生成相关广告
- 根据关联分数对搜索结果进行排序,在网页中显示
- 对索引和文件生成副本,用于提高request-level parallelism
Lecture_Bonus
-
进程与线程
CPU执行一个函数的本质是那么把该函数对应的第一条机器指令的地址写入PC寄存器,而机器指令要加载到内存中执行,需要记录下内存的起始地址和长度,同时要找到函数的入口地址并写到PC寄存器中——这正是构建进程的思路
1
2
3
4
5
6struct process{
void* start_addr;
int len;
void* start_point;
};
常规程序中,main()是第一个执行的;但是我们能先执行其它函数吗?能!因为main()和其它函数并无本质区 别,既然可以把PC寄存器指向main(),就也可以把PC指向任何一个函数;而当我们指向非main()函数的时候,**线程(thread)**就诞生了
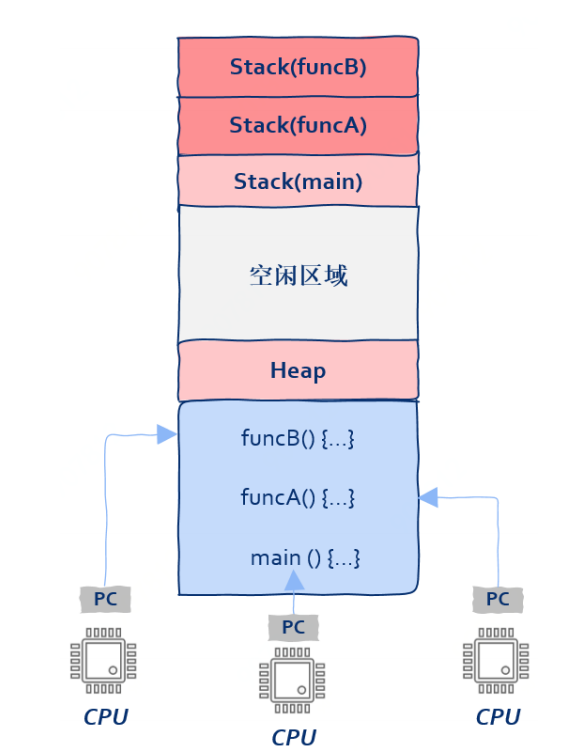
那么进一步解放思想——一个进程内有多个入口函数,也就是说同一个进程中的机器指令可以被多个CPU同时执行,即多线程并发
💡 PS.
- 并不是一定得有多核才能多线程,单核同样可以,因为线程是OS层面的实现,与有多少个核心无关,CPU在执行机器指令时也意识不到执行的机器指令属于哪个线程
- 上述理论也说明了为啥OS要给每个线程分配一个栈,因为每个线程的执行流都需要保存自己正在执行的函数的数据(参数、局部变量、返回地址等)
-
线程池
**motivation:对于短任务(一次网络请求、数据库查询),若来一个请求就创建一个进程,用完再摧毁,则即耗时间又费内存;如果你是公司老板,和“来一个任务招一个人”相比,更好的办法当然是招一批人养着,有事做事,没事躺尸,这就是线程池(thread pool)**的由来
**基本结构:**队列结构,生产者提交任务,消费者消费任务
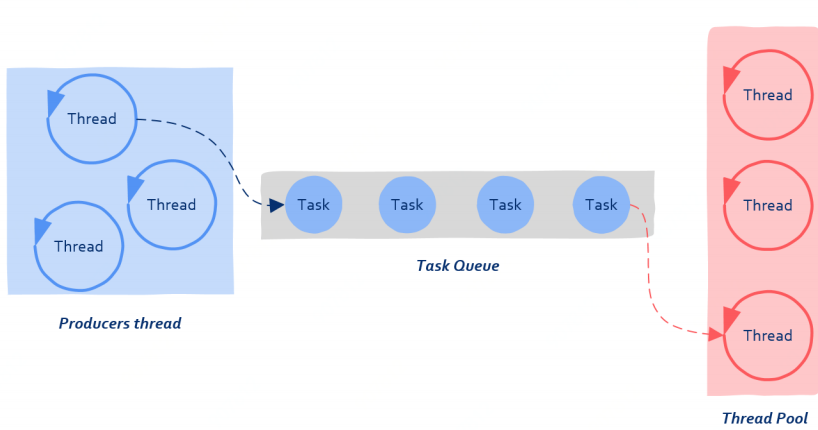
提交给线程池的任务包含两部分:需要被处理的数据和处理数据的函数
1
2
3
4struct task {
void* data; // 任务所携带的数据
handler handle; // 处理数据的方法
}生产者向队列中写入数据后,线程池中的某个线程会被唤醒,该线程从队列中取出上述结构体,执行:
1
2
3
4while(true) {
struct task = GetFromQueue(); // 从队列中取出数据
task->handle(task->data); // 处理数据
} -
核数与线程数的关系
结论:没有直接关系,一个核可执行多个线程
Q:那么线程数为多少时性能最佳捏?
A:如果线程不涉及任何I/O、没有任何同步互斥的纯计算类型,那么每个核心一个线程通常是最佳选择;但通常来说,线程都需要一定的I/O,可能需要一定的同步互斥,那么此时适当增加线程可能会提高性能,但线程数量达到一个临界值后性能会开始下降,这时线程间切换的开销将显著增加。
-
一段典型riscv代码
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25#打印第n个斐波那契数
.data
.word 2, 4, 6, 8
n: .word 9
.text
main:
add t0, x0, x0
addi t1, x0, 1
la t3, n
lw t3, 0(t3)
fib:
beq t3, x0, finish
add t2, t1, t0
mv t0, t1
mv t1, t2
addi t3, t3, -1
j fib
finish:
addi a0, x0, 1
addi a1, t0, 0
ecall # print integer ecall
addi a0, x0, 10
ecall # terminate ecall.data和.text是伪操作指令,表示将接下来的代码分配到data区和text区,.word表示按字(32bit)分配数据,即data区的第一个word放入0x02(多余的bit补零),第二个word放0x04这样子 la表示把n的地址给到t3,lw则是把n的地址中存的值放入t3中,即t3中的值变为9,la和lw通常配套使用 fib标签中的内容就是不断判断比较累加得斐波那契数了 最后的ecall是系统调用,由参数决定具体调用内容,a0和a1都是参数 (argument) 寄存器,用于在函数调用过程中保存第一个和第二个参数,以及在函数返回时传递返回值。ecall 1就是print,ecall 10就是exit
-
流水线寄存器

流水线的基本原理如此,上面的笔记也探讨过,那具体应该怎么实现捏?或者说,普通的串联组合逻辑电路怎么就不能实现pipeline捏?
实现方法:加流水线寄存器。如我们能把指令存储器输出的指令编码事先保存下来,那就可以提前更新PC寄存器的值,并用这新的值去指令存储器当中取出一个新的指令,而在取新指令的同时,刚才取出的那条指令的编码就会被分解成不同位域,而寄存器堆也会根据输入送出对应寄存器的内容。由此就实现了各个阶段分别运行,互不干扰。
打个比方,小志年轻力壮,搬快递时猛得一p,后面接手的老师傅说哎呀我要摸鱼,年轻人你只管搬你的别管我们(流水线思想),你速度快,多搬出来的那些放旁边小车上就好,待会我直接从小车上取就行(小车就是流水线寄存器)
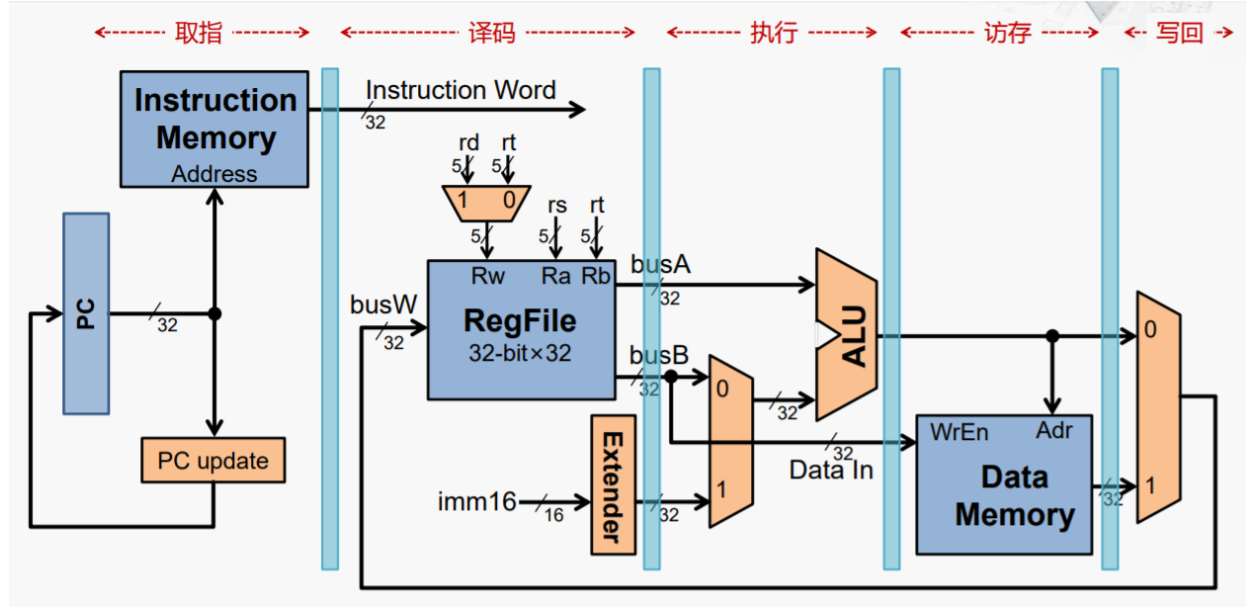
性能分析,与之前的流水线相比,多了流水线寄存器的延迟,周期200到250ps
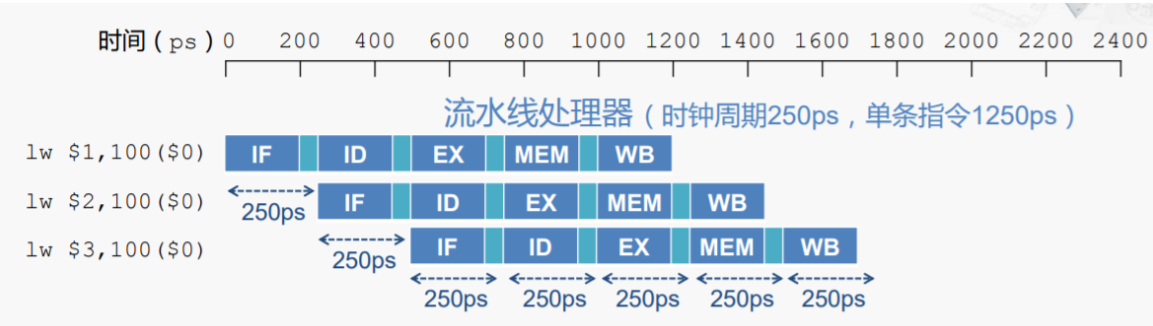
而至于为什么不加寄存器就不能实现流水线,我想应解释为各部分时延不匹配造成的线路信号冲突,即如果后面部分还没执行完,IF就在一直吭哧吭哧取指,那么取出来的instruction word想必不会被ID接受,也就成了无效输入
-
cache命中时,策略为回写(write back)和直写(write through); 未命中时,策略为写分配(write-allocate)和无写分配(no write-allocate),写分配表示发生write miss时,把没命中的那个块放到cache中,而无写分配则意味着只改memory 通常,write back和write-allocate搭配使用,这样的memory永远不会被直接修改;write through和no write-allocate搭配
-
用指针非空判断数组边界?
1
2
3
4
5
6
7
8
9
10
11
12
13
14#include <stdio.h>
#include <stdlib.h>
int main(int argc, char* argv[]) {
int array[4] = {1, 3 , 5, 7};
int* ptr = array;
while(ptr != NULL){
printf("%d\\n", *ptr);
ptr += 1;
}
return 0;
}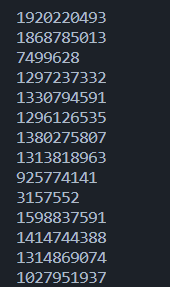
输出结果相当炸裂,这是为什么捏?
因为用指针非空判断数组边界本就是错的!数组大小为4不代表第五个内存空间就没有其它东西了啊!(下面这段代码也可以说明这一点,两个数组分别申请,但内存位置是连续的)
1
2
3
4
5
6
7
8
9
10
11
12
13
14#include <stdio.h>
#include <stdlib.h>
int main(int argc, char* argv[]) {
int array[4] = {1, 3 , 5, 7};
int array2[4] = {9, 10 , 11, 12};
int* ptr = array;
for(int i = 0; i < 8; i++){
printf("%d\\n", *ptr);
ptr += 1;
}
return 0;
}
也就解释了为什么C语言中反复强调,传数组指针时,也必须显式地将数组长度传进去;光通过一个数组指针是没办法获取数组长度的!(char数组用strlen()除外) 而至于为啥在过去的代码中好像用过“指针非空”来判断边界呢。。是因为使用场景是链表,链表初始化就把next指针设为nullptr了;而像vector的边界判断,那也是用的vector.end(),是个迭代器,而不是普通的一个nullptr。。