一个典型的cache工作原理演示实验
前言:本文章将在可视化环境下对cache工作原理进行演示实验,通过下面三个实验,读者应能:
- 理解cache三种访问模式(直连、两路相连、全连)的工作原理;
- 学会计算命中率(hit rate),并理解各个参数(循环次数、步长、cache size等)如何影响hit rate;
- 理解不同的cache策略(回写、直写、LRU)对hit rate的影响;
- 知道如何优化代码,以实现更高的hit rate
可视化平台:venus
PS. 完整的题目和描述请参考CS61C(20-SUMMER)- lab 7!下述所有分析仅相当于是实验答案,对题目本身不再赘述😪
汇编对应的C代码:
1 | |
实验一:直接映射
参数设置为:
- Array Size (a0): 128 (bytes),即32个int
- Step Size (a1): 8
- Rep Count (a2): 1
- Option (a3): 0
- cache line设为8byte,共4个line
- 策略为direct map + LRU
手动分析,一次for循环中,要访问array[0、8、16、24]这4个元素,访问array[0]时,cache miss(此时cache中还没东西),于是从memory中把array[0、1]都放进来;但下一次访问array[8]时仍然会miss,这么一路下来cache access为4,hit rate为0
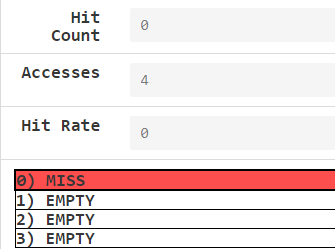
经验证确实如此,注意为啥只在cache0上操作捏?
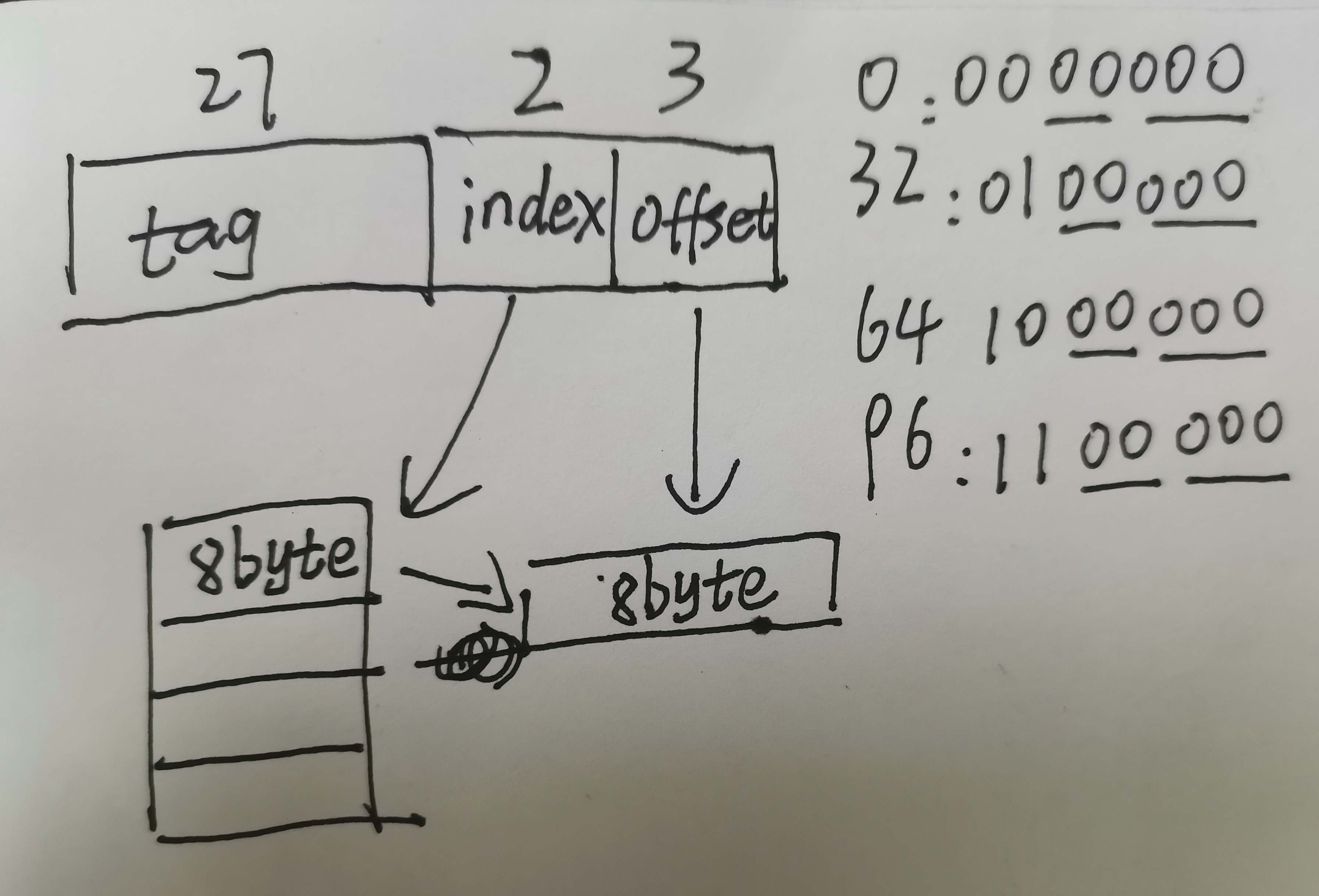
看图就清楚了:index 2bit,offset 3bit。访问的是array[0、8、16、24]这几个元素,地址为0、32、64、96,其二进制的index一样的,都是对应line0
那么同理,我们把stepsize改成4、2,hit rate始终都是0;
改成1则hit rate=50%
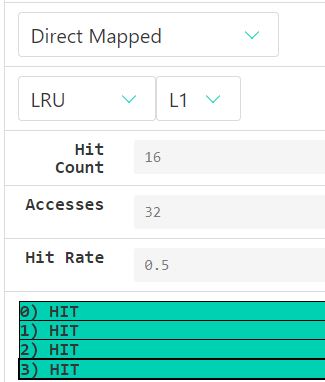
实验二:4路映射
参数设置为:
- Array Size (a0): 256(bytes),即64个int
- Step Size (a1): 2
- Rep Count (a2): 1
- Option (a3): 1
- cache line设为16byte,共16个line
- 策略为4 way set associative + LRU
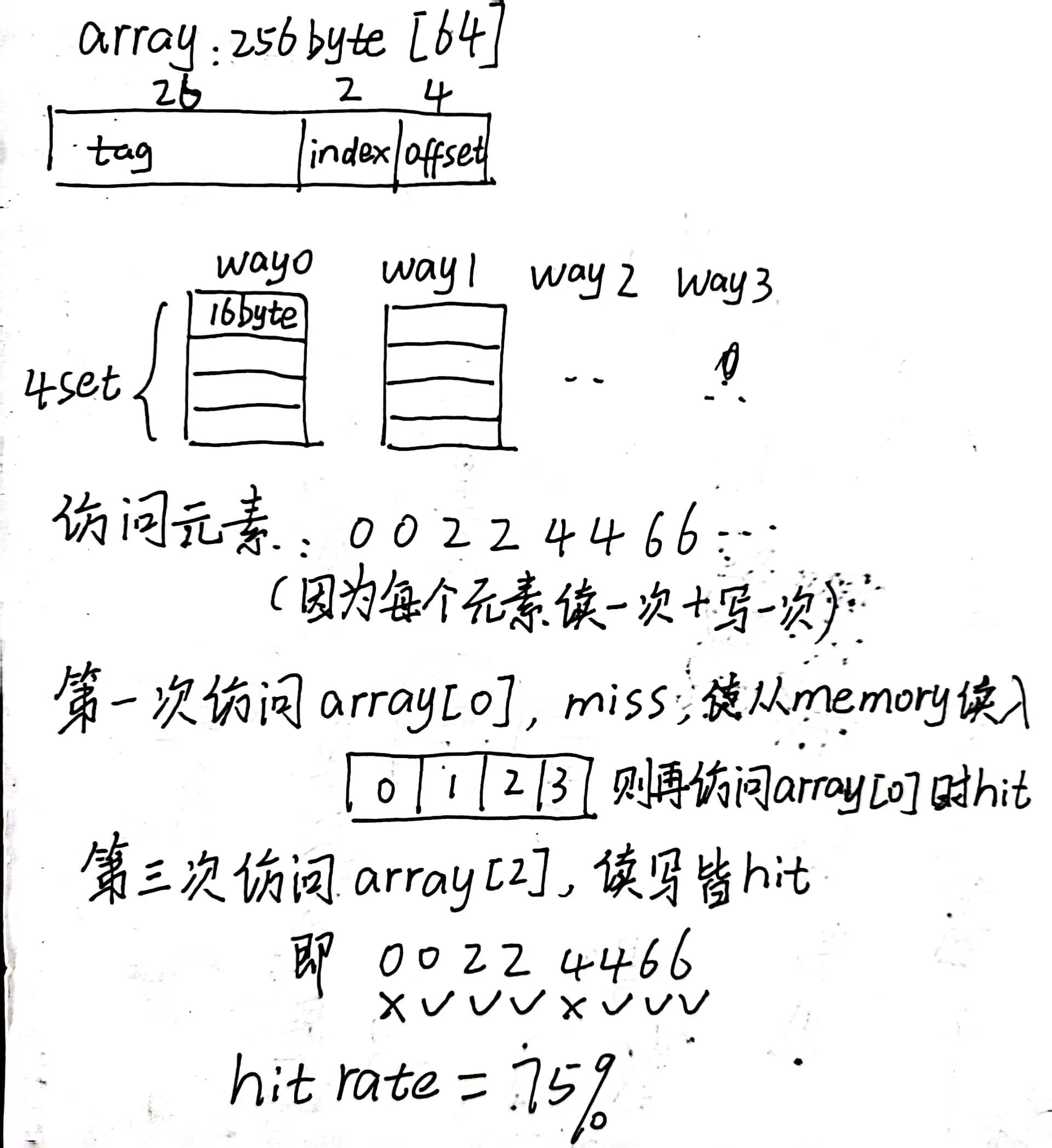
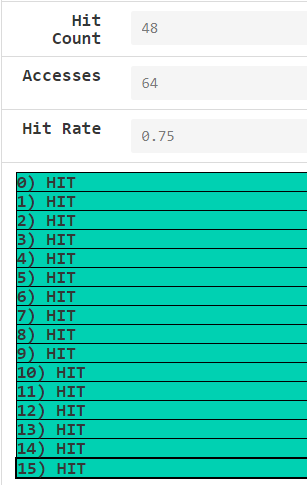
手动分析hit rate = 0.75,经验证确实如此
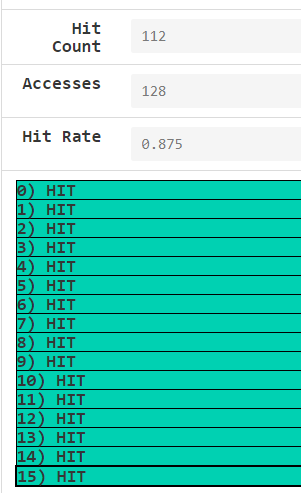
进一步思考:那把repcount设为2,hit rate还是0.75吗?
显然不是,因为第一遍for把所有cache line都填满了(整个array[]正好全装进去了!),所以后续每次cache access都会命中;hit rate = (48+64)/(2*64) = 0.875
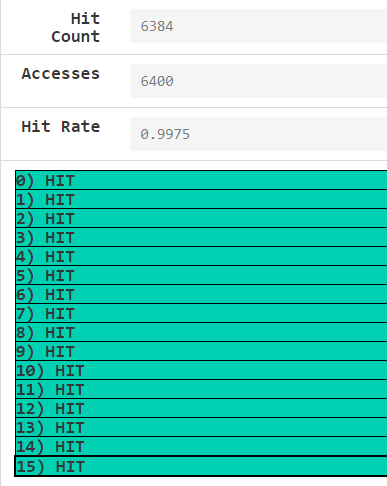
repcount设为100时,hit rate就很接近于100%了(这其实也是映证了cache的基本原理,时空局部性,即数据重复度越高,cache越管用)
实验三:两级cache
参数设置为:
- Array Size (a0): 128(bytes),即32个int
- Step Size (a1): 1
- Rep Count (a2): 1
- Option (a3): 0
L1 cache:
- cache line设为8byte,共8个line
- 策略为direct map + LRU
L2 cache:
- cache line设为8byte,共16个line
- 策略为direct map + LRU
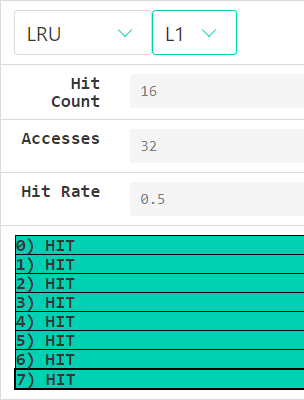
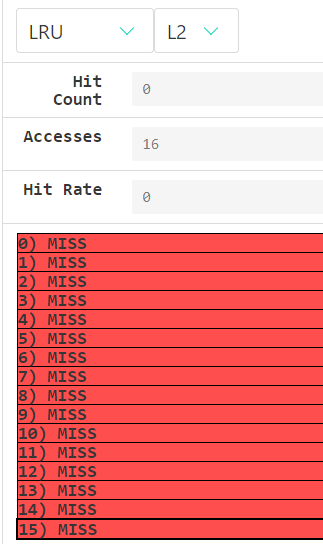
解释:
L1 hit rate 50%不解释,同实验一;
L2为啥是0%捏? 其实想想那个过程就清楚了:找array[0]的时候,L1、L2都miss,然后从memory中把array[0、1]拿出来,接下来访问array[1]的时候在L1里就直接找到了,根本不会去访问L2,所以L2一共也就会访问16次,次次miss
**Q:**改变哪个参数会让L1命中率不变且L2命中率增加?
**A:**rep count。因为增加for重复次数时,L1中始终只装了一半的array,永远都是第一个元素miss、第二个hit;而L2 cache size为128bytes,刚好能把整个数组装下,所以rep count越大,L2的hit rate越接近于100%
$$
$$