《南京大学操作系统笔记》
课程来源:NJU-OS(22 spring)
课程视频:https://space.bilibili.com/202224425/channel/collectiondetail?sid=192498
《南大OS笔记》@qlhhahaha
Lecture0、基础知识补充
-
ECF(Exceptional Control Flow,异常控制流)
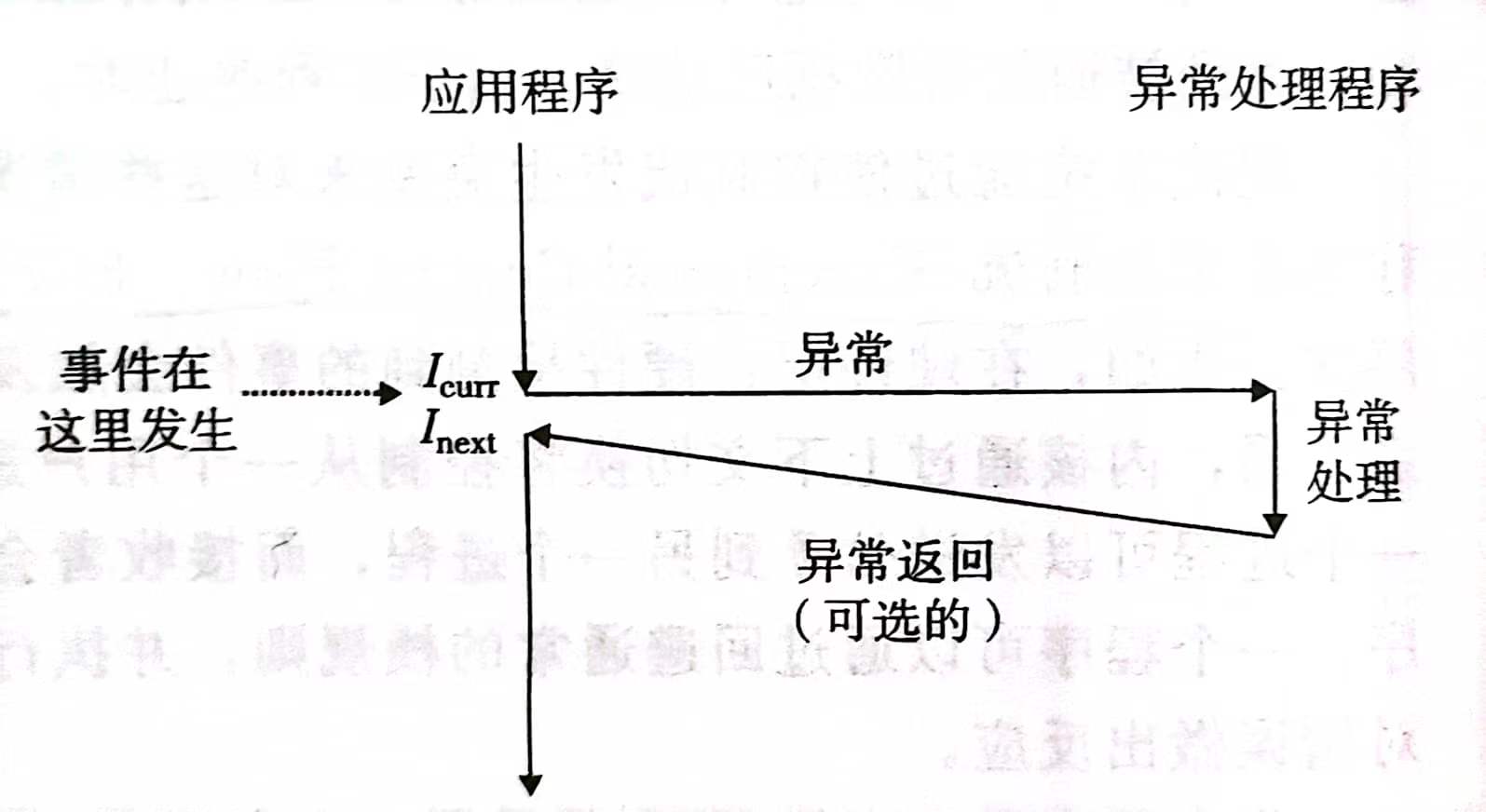

💡 PS. 中断是异常的一种,除它外还有故障中止、系统调用等异常类型
- bootloader
也是一个独立的程序,体量小,是系统上电后执行的第一段代码,在完成CPU和相关硬件的初始化之后,再将操作系统映像装载到内存中,然后跳转到操作系统所在的空间,启动操作系统执行
-
操作系统内核启动过程
- CPU Reset:CPU执行复位向量的指令,通常指向0xFFFF0(32位)或者0xFFFFFFF0(64位),这个地址是主板ROM上的BIOS/UEFI入口
- firmware(主板ROM装的BIOS/UEFI):bios查询可以用来启动操作系统的存储设备
- **bootloader:**加载并引导操作系统内核
- **Kernel_start():**执行操作系统内核以及启动各种服务
Lecture1、概述
-
操作系统是什么?
-
设计\应用视角:操作系统=对象+API(对应课程的Mini Lab,使用OS API实现黑科技代码)
-
实现\硬件视角:操作系统=C程序(对应OS Lab,自己动手实现一个真正的操作系统)
-
-
程序=状态机
C程序也是一个状态机模型,其中状态即堆+栈,执行一条语句即实现状态的迁移

-
如何在程序的两个视角之间切换?
通过编译器完成

编译(优化)的正确性(soundness):
S与C的可观测行为严格一致,即C代码状态机上所有不可优化的barrier都被正确地翻译到汇编上
Lecture2、多处理器编程 && 并发程序执行
- 并发(concurrency)和并行(parallel)
- 并发:一个处理器处理多个任务,实际上先后执行,看起来同时发生
- 并行:多个处理器(或单处理器的多核)同时处理多个不同任务,物理上真正同时
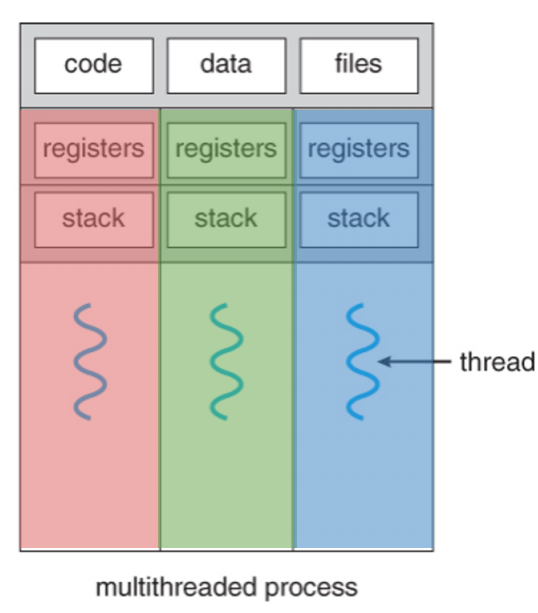
- 并发的基本单位:线程
各个线程有自己的PC、寄存器、栈空间,但全局的静态空间是共享的
-
并发牺牲了什么?
-
原子性
案例:山寨多线程支付宝
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21#include "thread.h"
unsigned long balance = 100;
void Alipay_withdraw(int amt) {
if (balance >= amt) {
usleep(1); // unexpected delays
balance -= amt;
}
}
void Talipay(int id) {
Alipay_withdraw(100);
}
int main() {
create(Talipay);
create(Talipay);
join();
printf("balance = %lu\n", balance);
}输出结果:

解释:
“程序由独占处理器执行”的基本假设在现代多处理器系统上不再成立。对于单处理器多线程来说,线程在运行时可能被中断,切换到另一个线程;对于多处理器多线程来说,线程根本就是并行执行的
解决方法:
线程池
-
顺序

-
可见性
简单地说,现代处理器也是一个动态的编译器,单个处理器会把汇编代码“编译”更小的微op,每个微op都有Fetch、Issue、Execute、Commit四个阶段

-
这样的“乱序”导致了可见性的丧失
解决方法:

-
关于互斥算法的一个失败尝试
能否通过下面这种方式来实现互斥算法捏?
具体来说,比如通过加锁来实现互斥
1
2
3
4
5
6
7
8
9
10
11
12
13int locked = UNLOCK;
void critical_section() {
retry:
if (locked != UNLOCK) {
goto retry;
}
locked = LOCK;
// critical section
locked = UNLOCK;
}答案是不行,比如,可能两个线程几乎同时绕过 if 检测,然后上两次锁,并都执行critical section
-
另一个成功的尝试:Peterson算法

为什么可以实现互斥呢?我们可以通过分类讨论来定性理解一下:
- 假如A想上厕所但B不想:此时A举旗,发现B没举,OK,那他直接去上就行
- 假如A、B同时想上厕所:同时举旗,然后同时往厕所门上贴标签,谁手速快最后门上就是谁的名字(因为贴的是对方的名字,所以先贴的那个会被后贴的那个覆盖掉——看起来互相谦让,其实最后还是自私拼手速)。假设A手速更快,那么最后标签就是“A正在使用”,则A进、B等待
💡 PS. “互相贴对方名字”(谦让turn)这个设定其实很有趣,因为如果只举旗而不贴标签的话,那么同时举旗后没办法保证谁进谁不进——这正是上面第4点算法的失败之处
Lecture3、互斥与同步
-
提出锁机制的motivation
在共享内存上实现互斥的根本困难:不能同时读/写内存。
怎么说?想象物理世界中,大家都想上厕所,所以同时去拿厕所钥匙。谁拿到钥匙,就同时触发了“我get了钥匙”和“对其他人来说,钥匙无法被get”两件事 —— 言下之意,物理世界中的读写操作是原子性的!读和写可以在一瞬间被同时完成!
那在计算机世界中是这样吗?显然不是,线程A读出这把钥匙后,还要花时间再去改写钥匙状态(哪怕耗时很少);那么在这段时间里,线程B可能也会读出这把钥匙,最终导致互斥失败。
顺着上面的思路,我们很容易想到:欸,那如果我们找到一种原子性的读写方式,是不是就可以和物理世界一样,解决这个问题了捏?
-
自旋锁(Spin Lock)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15//实现互斥:自旋锁
int key = YES; //值为YES表示钥匙可用
void lock() {
retry:
int got = xchg(&key, NOPE);
if (got == NOPE)
goto retry;
assert(got == YES);
}
void unlock() {
xchg(&key, YES)
}其中 got = xchg(&table, NOPE) 即是一条原子性的交换指令,它表示同时完成”取出table的值给到got“和”把NOPE写入table“两个操作
想想,为啥有了这个操作,就能实现互斥?
假设线程A第一个拿到钥匙,也就是用 xchg 取出钥匙并写入NOPE(这个操作过程是原子的,所以其它线程干扰不了),那么它会跳过下面那个 if ,直接进入critical section(临界区);而对于其它后来的线程,再试图用 xchg(&table, NOPE)取钥匙时,会发现里面的值已经是NOPE了,那么就会在下面的 if 判断里空转(所谓**”自旋“**就是这个意思)。直到线程A执行unlock(),钥匙里的值重新变为YES,其它线程才有机会进入临界区。
上述代码也可以简写为下列形式(更常见):
1
2
3int locked = 0; //0表示钥匙可用
void lock() { while (xchg(&locked, 1)) ; }
void unlock() { xchg(&locked, 0); }💡 PS. 用python实现自旋锁时,会发现只需要用一行 x, y = y, x 就可以实现原子性的交换 —— 再次映证人生苦短我用py的真理。。
-
自旋锁的缺陷和应用场景
由自旋锁的实现机制,可以自然而然地想到它有以下缺陷:
-
自旋(共享变量)会触发处理器间的缓存同步,延迟增加:一旦一个线程改变了共享变量,就要在各个cpu的缓存之间同步,而缓存一致性本身会增加开销
-
除了进入临界区的线程,其它处理器上的线程都在**空转,**且争抢锁的处理器越多,利用率越低
-
获得自旋锁的线程可能被操作系统切换出去,从而造成100%的资源浪费
我们可用下列代码进行性能测试:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29#include "thread.h"
#include "thread-sync.h"
#define N 10000000
spinlock_t lock = SPIN_INIT();
long n, sum = 0;
//自旋锁
void Tsum() {
for (int i = 0; i < n; i++) {
spin_lock(&lock);
sum++;
spin_unlock(&lock);
}
}
int main(int argc, char *argv[]) {
assert(argc == 2);
int nthread = atoi(argv[1]);
//把一个求和任务分给nthread个线程做
n = N / nthread;
for (int i = 0; i < nthread; i++) {
create(Tsum);
}
join();
assert(sum == n * nthread);
}
当线程数分别为1、2、4、32时:
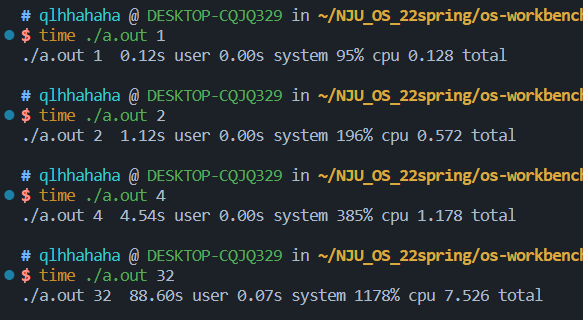
奇怪的事情发生了!随着线程数增加,耗时不增反减,这映证了上面分析的自旋锁的缺陷
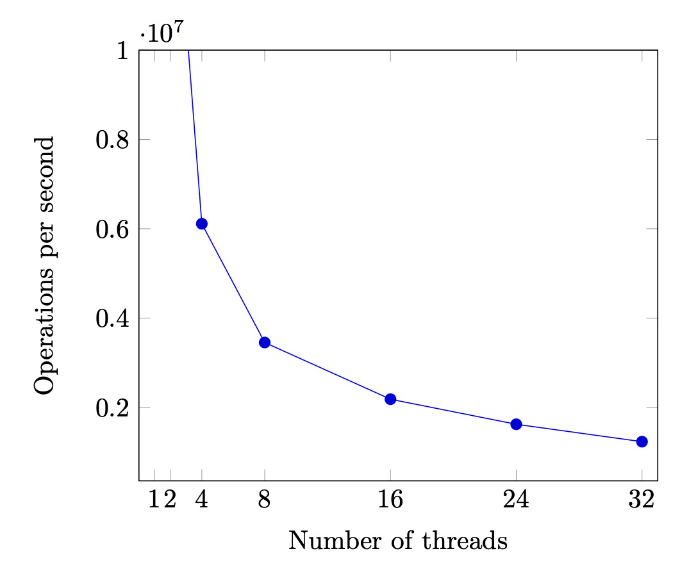
那么自旋锁应该应用在哪些场景呢:临界区短、几乎不拥堵;持有自旋锁时禁止执行流切换
具体场景如:操作系统内核的并发数据结构(短临界区)
在这个场景下,操作系统可以关闭中断和抢占,保证锁的持有者在很短的时间内可以释放锁
-
互斥锁(Mutex Lock)
分析完上面自旋锁的缺陷后,一个自然而然的思路就是:其它线程无法进入临界区时,能不能让它们去做其它事,而不是搁那儿自旋干等呢?
这就是互斥锁的思想:用系统调用实现锁操作

互斥锁和自旋锁比较:

-
Take-away message
- 自旋锁 —— 软件不够,硬件来凑
- 互斥锁 —— 用户不够,内核来凑
可见,解决问题的一个常用思路是找到你所依赖的假设,并大胆地打破它(解决提出问题的人)
-
生产者-消费者的同步
motivation:单纯实现互斥是不够的,比如要两个线程按序打印左括号和右括号,那必须还要在某种程度上实现同步

一个自然而然的思路对两个线程分别设置条件,不满足的时候自旋等待,满足则执行
1 | |
💡 PS. 上述代码的一个细节是,条件不满足时我们必须释放锁 —— 如果不释放锁,其它生产者/消费者就无法继续工作,造成死锁
这样确实能得到正确结果,但最大的问题就是一个线程执行时其它线程不断goto、retry,空耗cpu资源
-
条件变量
为了解决上述问题,我们理想中的同步API应该长这样:一个线程满足条件时执行,不满足则等待(线程wait不消耗cpu资源)
1 | |
具体实现代码如下:
1 | |
分析:
- 执行Tproduce()时首先上锁,然后检验条件发现成立,于是执行临界区,结束后用broadcast唤醒所有睡眠中的线程,并释放锁;与此同时对于Tconsumer()来说,若不满足条件则进入睡眠等待状态,直至被其它线程唤醒
- 条件判断中使用 while(!CAN_PRODUCE) 而不是 if(!CAN_PRODUCE),因为如果用 if 的话,被从睡眠中唤醒后直接进入后面的临界区,但事实上此时并不一定满足条件!从而造成”假唤醒“,括号打印错误
- 在调用 wait(cv, mutex) 之前必须保证已经获得mutex。wait会释放mutex并睡眠,被唤醒时wait又会重新试图获得互斥,直到获得互斥锁后才能返回
我们可以通过上述代码总结出用条件变量进行同步的通用模板:
1 | |
-
信号量(semaphore)
P —— 从袋子里取出一个球
V —— 放入一个球
球 —— 一个单位的资源
1 | |
-
防御性编程
狂加assert,不断检查、检查、检查
Lecture4、操作系统上的进程
-
fork():做一份状态机完整的复制(内存、寄存器现场)

1 | |
输出结果:
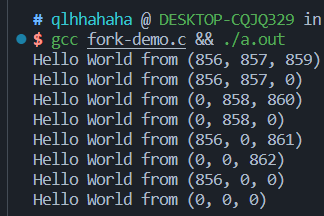
理解:一生二,二生四,四生八
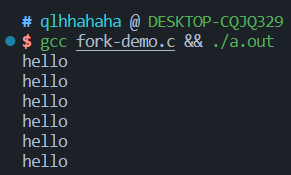
- 一段魔法代码:
1 | |
直接将结果输出到终端的时候,有6个hello
但输出到管道或者文件时,神奇的事情发生了,有8个hello
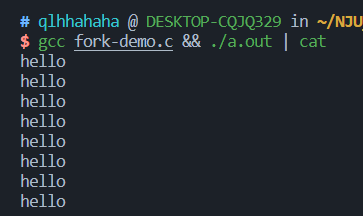
解释:
“直接写到终端”与“写到管道或文件”两种情况下的缓冲策略是不一样的,前者遇见换行符就刷新,后者则会等缓冲区满才会刷新。 对于直接写到终端,fork之 后有两个进程,printf输出两个hello到终端,再fork一次得4个进程,输出4个hello到终端; 而对于写到管道,fork之后有两个进程,printf在进程的buffer中 各写入一个hello,再fork一次得4个进程(注意,这4个进程的buffer中都存了一个hello!),各进程再printf一次,则四个进程的buffer中都有两个hello, 于是最后输出8
-
execve():将当前运行的状态机重置为另一个程序的初始状态

-
_exit():立刻摧毁状态机

Lecture5、进程的地址空间
- 定义
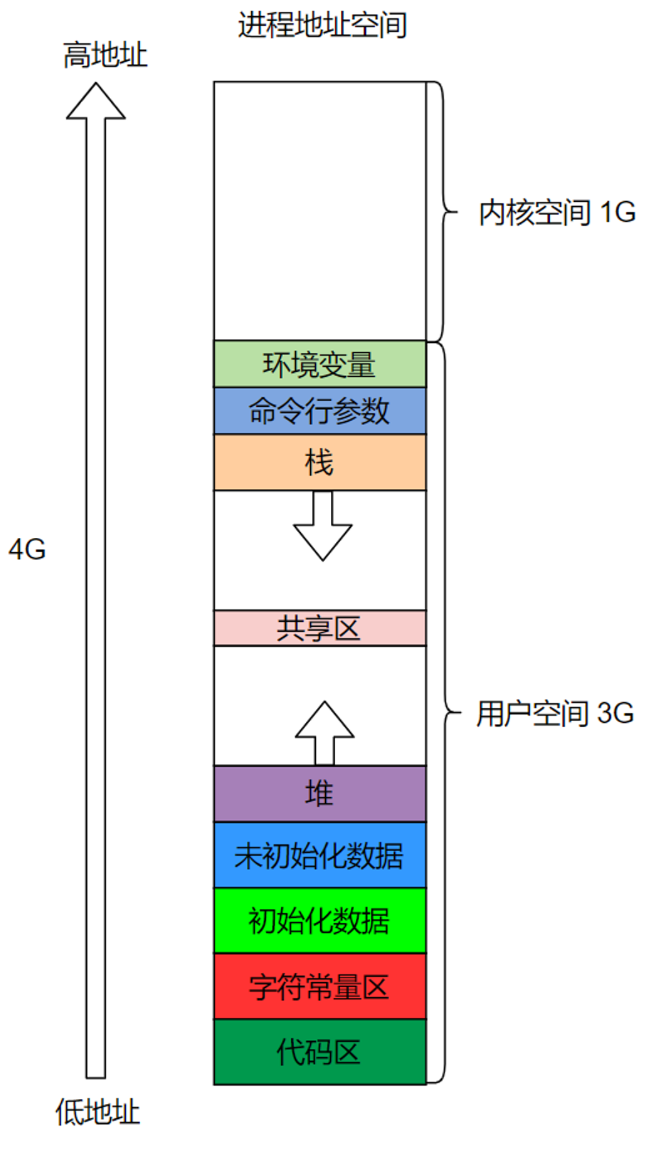
- 合法的地址
- 代码 (main, %rip 会从此处取出待执行的指令),只读
- 数据 (static int x),读写
- 堆栈(int y),读写
- 运行时分配的内存(???),读写
- 动态链接库(???)
- 非法的地址
- NULL,导致segmentation fault
-
查看进程的地址空间
pmap:report memory of a process
用gdb查看当前执行的进程的进程号,再用pmap查看进程的地址空间

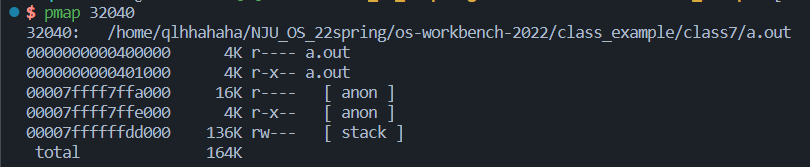
可见进程的地址空间是若干连续的”段“,”段“的内存可以访问,不在段内/违反权限的内存访问会触发SIGSEGV
-
vdso:virtual system calls
linux中系统调用十分消耗CPU资源,因为syscall的本质是一种异常,当调用一个syscall时会触发 CPU 异常,CPU 进入异常处理流程。CPU 在异常处理流程中可以识别到本次异常是由于syscall引起的,从而进入syscall的异常处理流程中。
但如果一个syscall是只读的,那么它或许不必陷入内核执行
如linux中的gettimeofday()
大致实现原理:在每个进程的地址空间都映射一个vitural var的页面,这个页面是所有进程都共享的,下列都是无需进入内核就得获取的syscall
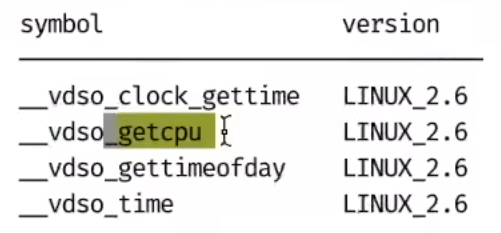
-
管理进程地址空间的系统调用

一般来说,修改一个文件的内容需要如下3个步骤:
- 把文件内容读入到内存中
- 修改内存中的内容。
- 把内存的数据写入到文件中
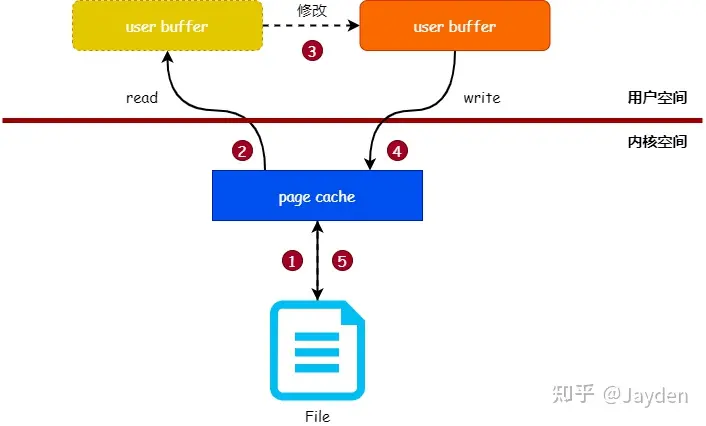
可以看出,页缓存(page cache) 是读写文件时的中间层,内核使用页缓存与文件的数据块关联起来,所以应用程序读写文件时,实际操作的是页缓存。
而mmap就是直接在用户空间读写,使用mmap系统调用可以将用户空间的虚拟内存地址与文件进行映射(绑定),对映射后的虚拟内存地址进行读写操作就 如同对文件进行读写操作一样
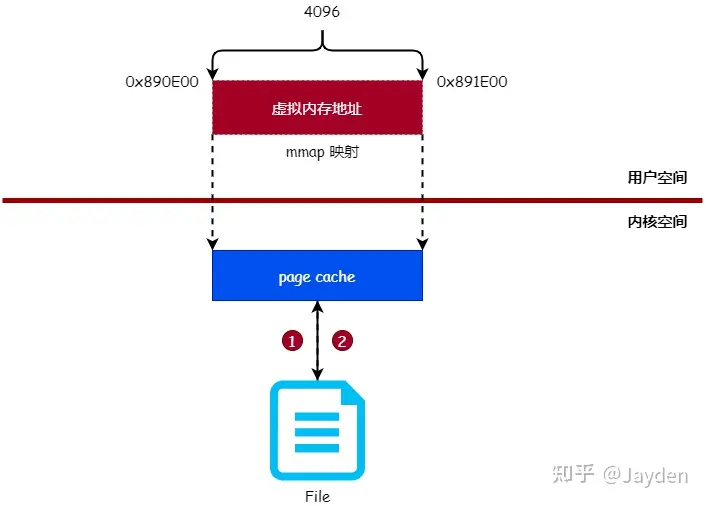
- 地址空间的隔离

进程的地址空间之间一般是相互隔离的,但有些应用也可以跨进程访问(如gdb,不然就没办法调试了,因为gdb自己就是个进程嘛)
但也有一些hack方法可以修改进程的内存,如游戏外挂、代码注入(hooking)
Lecture6、 系统调用和shell
-
motivation:用户不能够直接使用syscall,所以我们需要一个能把操作系统API封装起来的程序来帮助人类创建/管理进程、文件。。用户去和这个程序交互。
这个程序就是shell(内核kernel提供系统调用,shell提供用户接口)
-
shell
shell是一门**”把用户指令翻译为syscall“**的编程语言,可以把它理解为包裹kernel的一层外壳
- 重定向:ls > a.txt,将标准输出重定向到文件中
- 后台执行:ls &,让程序或脚本切换到后台执行
- 逻辑执行:gcc test.c && ./a.out ,当前一个命令成立时
-
gcc -static
gcc 编译, 有个选项是-static, 其作用是决定 编译-链接时, 使用的库是静态库还是动态库
-
静态库(常以a为结尾, 例如libxx.a)
在链接时**将需要的二进制代码都“拷贝”**到可执行文件中(注意, 只拷贝需要的,不会全部拷贝) 优点: 编译成功的可执行文件可以独立运行,而不再需要向外部要求读取函数库的内容; 缺点: 维护难, 每次更新, 都需要依赖方重新编译。另外, 依赖方因为拷贝了库的内容, 所以编译后的文件会比较大。
-
*动态库(常以so为结尾, 例如libxx.so):*
链接时仅仅“拷贝”一些重定位和符号表信息,这些信息可以在程序运行时完成真正的链接过程。 优点: 维护容易, 只要对外接口不变, 则库可以不停的更新, 依赖方不需要再次编译; 缺点: 依赖方运行时需要所有依赖的so库都存在。
综上:所以两者的本质区别是,该库是否被编译进目标(程序)内部
-
Lecture7、 C标准库的实现
-
零依赖(freestanding)环境
-
freestanding implementation:不能包含c标准库,只能包含基本的头文件

-
hosted implementation:能包含所有的c标准库
-
freestanding environment:在这种环境下编译的程序,不能包含完整的c标准库,甚至连main入口都没有,如kernal开发,c标准库开发
-
hosted environment:这种环境就是我们通常的编译环境,main作为入口,可以包含完整的c标准库
-
-
motivation
c标准库是对系统调用的封装
-
封装(1):纯粹的计算
-
字符串/数组操作:string.h
-
排序和查找:
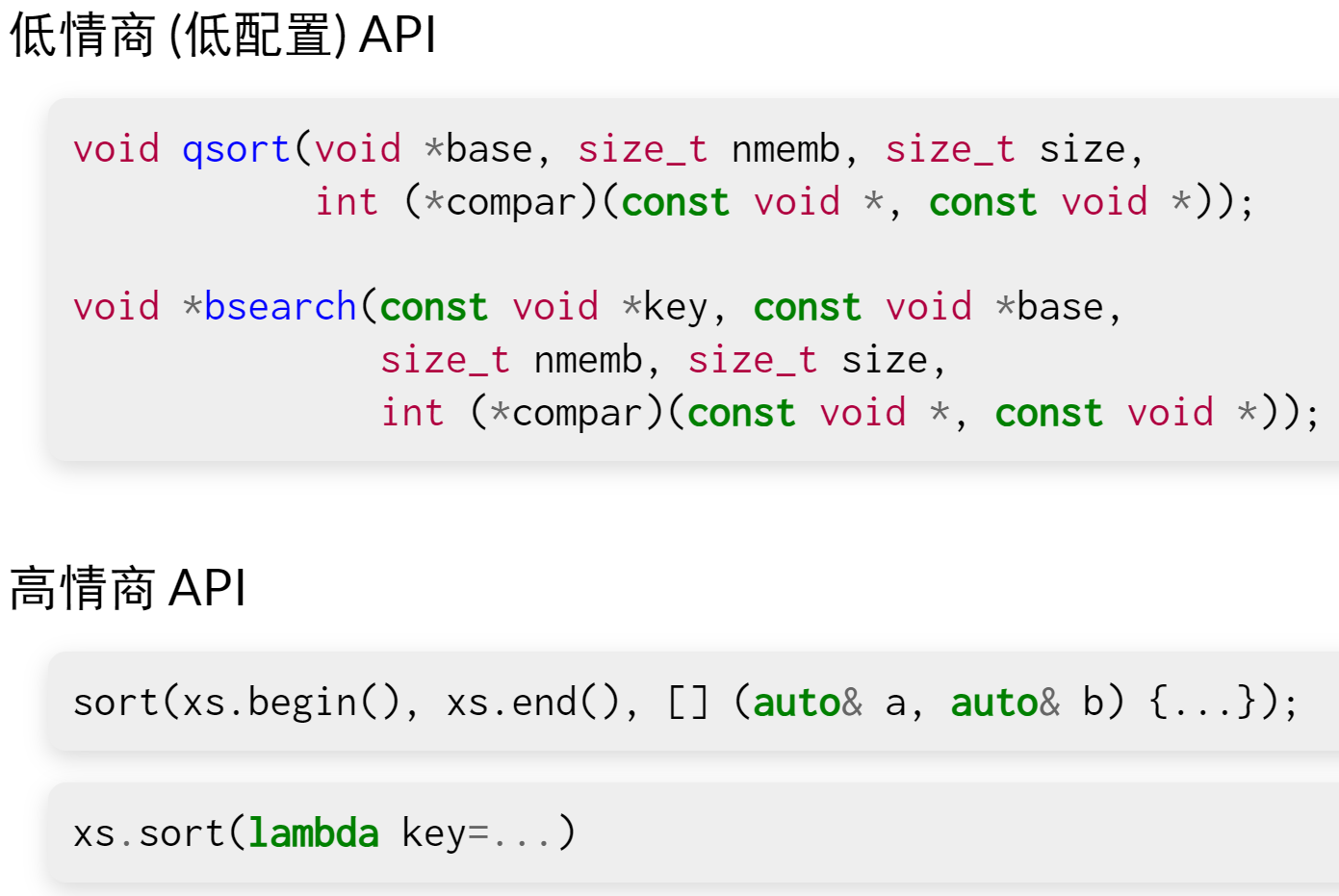
-
math.h、stdlib.h、setjmp.h。。。
-
-
封装(2):文件描述符
linux中一切皆文件,当进程打开现有文件或者创建新文件时,kernel向进程返回一个文件描述符(file descriptor,fd),它是一个非负整数值,指向被打开的文件,所有执行IO操作的syscall都会通过该fd
1 | |

为什么是3呢?因为0 1 2 被占用了
在UNIX系统中,系统创建的每个进程默认都会打开3个文件: 标准输入(0)、标准输出(1)、标准错误(2)
而这些整数的本质是什么呢 —— 文件指针数组files的index
一般来说,一个进程会从files[0]中读取输入,将输出写入files[1],将错误信息写入files[2]。比如printf向命令行打印字符,从进程的角度来看,就是向files[1] 中写入数据;同理,scanf就是进程试图从files[0]这个文件中读取数据
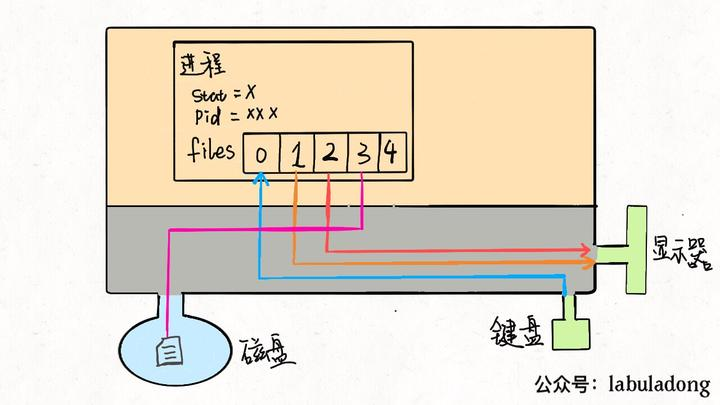
明白了上述原理后,输出输入重定向就很好理解了:输入重定向就是把files[0]指向一个文件,则程序会从这个文件中读取数据而不是键盘;输出重定向则是把 files[1]指向一个文件,那么程序的输出就不会写到显示器而是写入这个文件
1 | |
另外,管道符也可由此解释:把一个进程的输出流和另一个进程的输入流连接起来形成一条“管道”
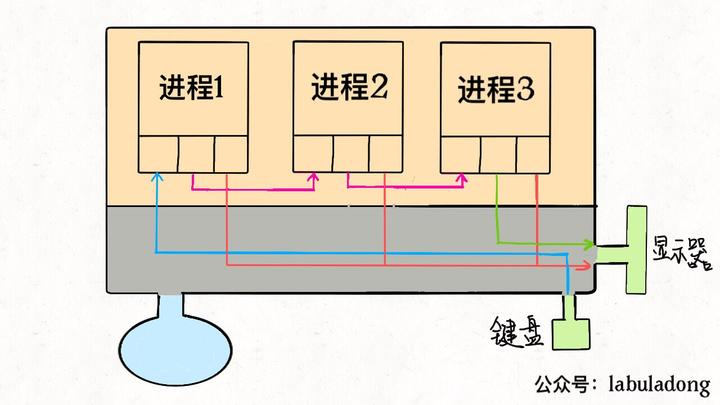
到这里也可以看出「Linux 中一切皆文件」设计思路的高明了,不管是设备、另一个进程、socket套接字还是真正的文件,全部都可以读写,统一装进一个简 单的files数组,进程通过简单的文件描述符访问相应资源,具体细节交给操作系统,有效解耦,优美高效。
💡 PS. 每个进程维护一个struct_task结构体,里面有一个files数组,数组大小(或者说fd的最大值问题可参考这篇文章)
-
封装(3):地址空间
malloc和free
Lecture8、可执行文件
-
理解
可执行文件的本质:一个描述了状态机的初始状态 + 迁移的数据结构

可执行文件是被execve()给调用的,把状态机重置为可执行文件的初始状态

-
chmod
chmod +rwx file:给file的所有用户增加读写执行的权限
-
编译链接

-
静态ELF加载器
将磁盘上静态链接的可执行文件按照ELF program header,正确地搬运到内存中执行
操作系统在execve时完成:
- 操作系统在内核态调用mmap
- 进程还未准备好时,由内核直接执行 ”系统调用“
- 映射好 a.out 的代码、数据、堆区、堆栈、vvar、vdso、vsyscall
- 更简单的实现:直接读入进程的地址空间
加载完成之后,静态链接的程序就开始从ELF entry开始执行,之后就变成我们熟悉的状态机,唯一的行为就是取指执行
1
readelf -h a.out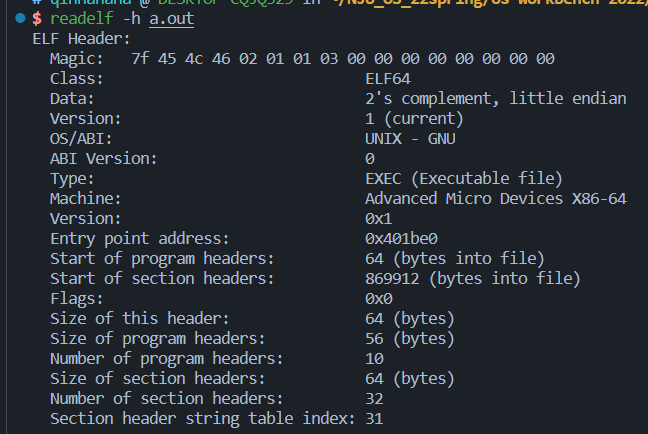
- 操作系统在内核态调用mmap
我们这里看到,程序的入口地址是:Entry point address: 0x401be0。我们接着用gdb来调试:

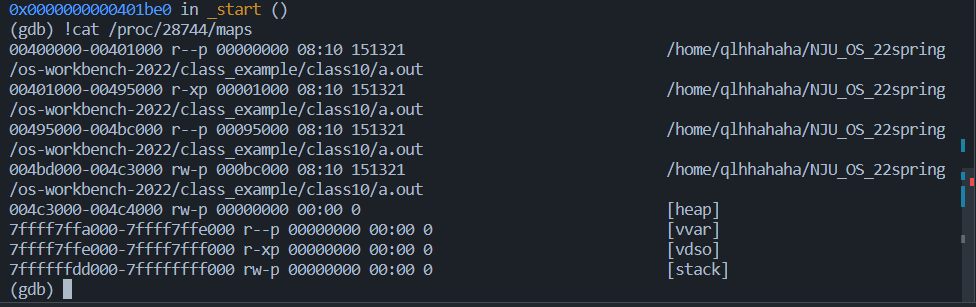
我们用starti来使得程序在第一条指令就停下,可以看到:
- 程序确实是从0x400180开始的,与我们上面查到的入口地址一致
- 而我们用cat /proc/[PID]/maps 来查看这个程序中内存的内容,看到我们之前提到的代码、数据、堆区、堆栈、vvar、vdso、vsyscall都已经被映射进了内存中。
调试的结果符合我们对静态程序加载时操作系统的行为的预期
Lecture9、xv6简介、上下文切换
-
xv6简介:
-
MIT6.S081课中的实验操作系统内核,posix标准,纯c,可运行在riscv上
-
接近完整的unix shell体验,具备基本工具集(wc、echo、cat。。)
-
命令执行、管道、重定向

-
-
处理器的虚拟化
一个问题:为什么死循环不能使计算机被彻底卡死?即使在执行一个永远while(1)的程序,也可以另开一个终端进行操作、也还能发送kill信号终止程序?



-
上下文切换
CPU总是能够支持远大于CPU数量的任务的经行,操作系统会“轮流”分配CPU供任务使用,这就要求CPU知道从哪里去加载任务以及从哪里开始或继续去加载任务,而这些信息都被保留在CPU的寄存器中,其中即将执行的下一条指令的地址被保存在程序计数器(PC)这一特殊的寄存器中,我们将寄存器的这些信息称为CPU的上下文,也称硬件上下文
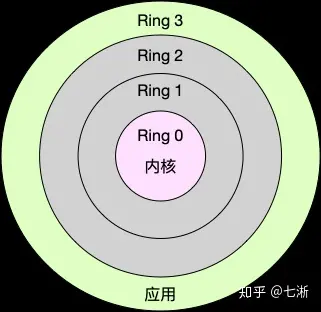
Linux 按照特权等级,把进程的运行空间分为内核空间和用户空间,分别对应着下图中, CPU 特权等级的 Ring 0 和 Ring 3。
-
内核空间(Ring 0)具有最高权限,可以直接访问所有资源;
-
用户空间(Ring 3)只能访问受限资源,不能直接访问内存等硬件设备,必须通过系统调用陷入到内核中,才能访问这些特权资源
-
进程既可以在用户空间运行,又可以在内核空间中运行。进程在用户空间运行时,被称为进程的用户态,而陷入内核空间的时候,被称为进程的内核态
-
上下文切换与系统调用的关系
从用户态到内核态的转变,需要通过系统调用来完成。
一次系统调用中的过程:
- 保存 CPU 寄存器里原来用户态的指令位
- 为了执行内核态代码,CPU 寄存器需要更新为内核态指令的新位置
- 跳转到内核态运行内核任务
- 当系统调用结束后,CPU 寄存器需要恢复原来保存的用户态,然后再切换到用户空间,继续运行进程
所以一次系统调用中发生了两次CPU上下文切换(用户态-内核态-用户态)
Lecture10、处理器调度
-
motivation:上下文切换机制是在中断\系统调用时执行操作系统代码,操作系统实现所有状态机(进程)一视同仁的“封存”,从而可以恢复任意一个状态机(进程)的执行。而具体选择哪个进程执行,就是处理器调度策略问题。
-
一些常见调度算法
-
先来先服务算法(FCFS: First Come, First Served)
FCFS依据进程进入就绪状态的先后顺序排列,它简单、易于实现

FCFS 对长作业有利,适用于 CPU 繁忙型作业的系统,而不适用于 I/O 繁忙型作业的系统
-
最短作业优先(Shortest Job First, SJF)
会优先选择运行时间最短的进程来运行,这有助于提高系统的吞吐量
这显然对长作业不利,很容易造成长作业等待过久的极端现象
-
-
时间片轮转算法(Round-Robin,RR)
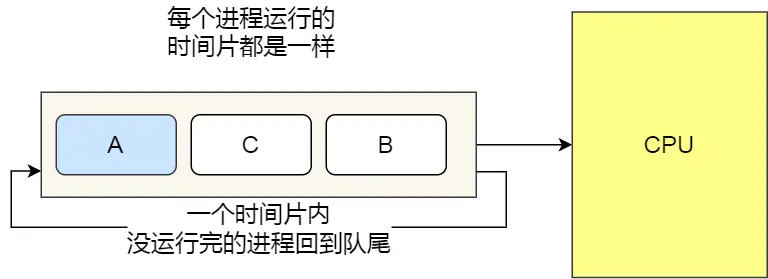
每个进程被分配一个时间段,称为时间片(Quantum),即允许该进程在该时间段中运行。
- 如果时间片用完,进程还在运行,那么将会把此进程从 CPU 释放出来,并把 CPU 分配另外一个进程;
- ·如果该进程在时间片结束前阻塞或结束,则 CPU 立即进行切换;
另外,时间片的长度就是一个很关键的点:
- 如果时间片设得太短会导致过多的进程上下文切换,降低了 CPU 效率;
- 如果设得太长又可能引起对短作业进程的响应时间变长
通常时间片设为 20ms~50ms 通常是一个比较合理的折中值
针对Round-Robin的一个改进策略:引入优先级(Linux中的nice)
用top查看进程优先级(NI那一列),为-19到20的整数,-19优先级最高,20最低(越坏、niceness越低,就越要去抢资源;越老好人就越会把资源让给别人)
完全基于优先级的调度策略在实时操作系统RTOS中应用较多,即容易把整个cpu资源给高优先级任务
linux:nice相差10,cpu资源获取率相差10倍

Round-Robin的一个问题:资源分配不均。如系统中有两个进程,一个是交互式的vim,单线程;另一个是32线程的计算进程,那么就会出现
- vim花0.1ms处理完输入就又等输入,马上主动让出cpu
- 计算进程使vim在有输入可以处理时被延迟,多线程长达数百ms的延迟导致卡顿
-
策略:动态优先级,多级反馈队列(MLFQ: Multi Level Feedback Queues)
顾名思义:
- 「多级」表示有多个队列,每个队列优先级从高到低,同时优先级越高时间片越短。
- 「反馈」表示如果有新的进程加入优先级高的队列时,立刻停止当前正在运行的进程,转而去运行优先级高的队列
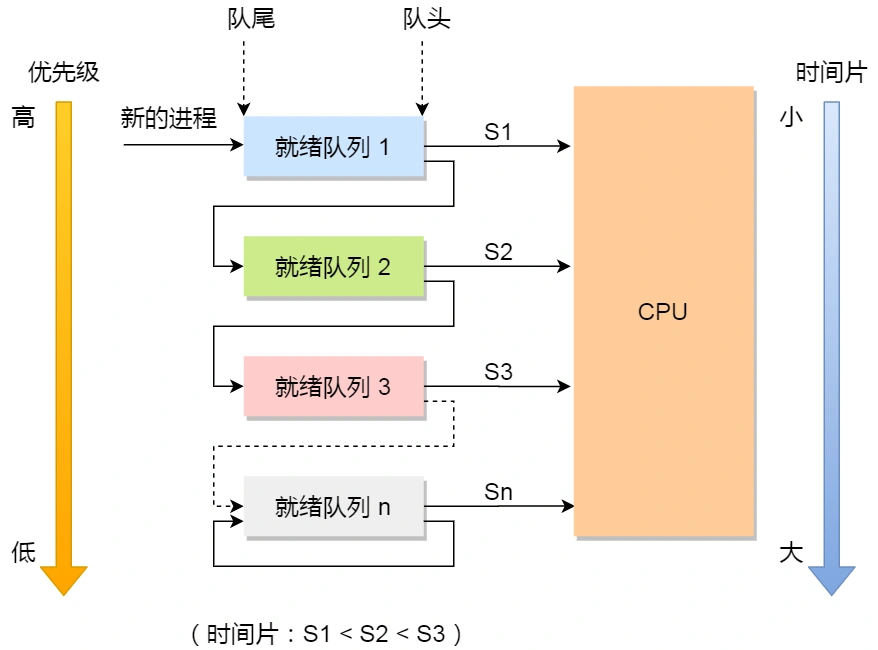
来看看,它是如何工作的:
- 设置了多个队列,赋予每个队列不同的优先级,每个队列优先级从高到低,同时优先级越高时间片越短;
- 新的进程会被放入到第一级队列的末尾,按先来先服务的原则排队等待被调度,如果在第一级队列规定的时间片没运行完成,则将其转入到第二级队列的末尾,以此类推,直至完成;
- 当较高优先级的队列为空,才调度较低优先级的队列中的进程运行。如果进程运行时,有新进程进入较高优先级的队列,则停止当前运行的进程并将其移入到原队列末尾,接着让较高优先级的进程运行;
可以发现,对于短作业可能可以在第一级队列很快被处理完。对于长作业,如果在第一级队列处理不完,可以移入下次队列等待被执行,虽然等待的时间变长 了,但是运行时间也会更长了,所以该算法很好的兼顾了长短作业,同时有较好的响应时间。
-
完全公平调度算法(CFS,Completely Fair Scheduler)
idea:取消时间片的概念,采用分配cpu使用时间的比例的方法。即两个优先级相同的进程在一个cpu上运行,则每个进程都将分配50%的cpu运行时间。而优先级不同时,优先级越高分配的权重就越多,占用cpu时长就越长
分配给进程的时间 = 总的cpu时间 * 进程的权重/就绪队列(runqueue)所有进程权重之和
CFS调度器中,nice值和权重之间可以互相转换,内核提供了一个array转换nice值和权重
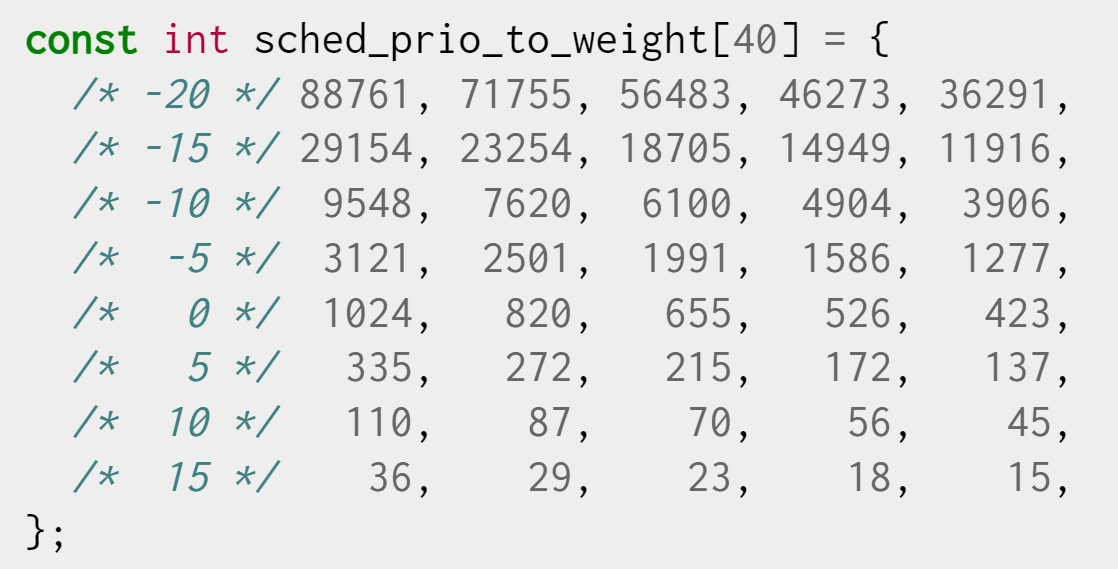
如进程A的nice为-1,B的nice为0,则:
$$
CPU\ usage\ of\ A=CPU\ time * \frac{1277}{1277+1024}=0.55*CPU\ time
$$
$$
CPU\ usage\ of\ B=CPU\ time * \frac{1024}{1277+1024}=0.45*CPU\ time
$$
💡 PS. 这也就是为啥说nice升高1,资源利用率大概差10%
接下来,更重要的是引入虚拟时间(virtual time)的概念,其核心思想是:虽然每个进程实际分配到的cpu使用时间不一样,但我们可以将其转化为数值一样 的虚拟时间,从而让操作系统觉得,“oh,酱紫是公平的,每个人的需求我都满足啦”
$$
virtual_runtime=real_time*\frac{1024}{weight}
$$
假如调度周期为10ms
则A的虚拟时间为$10ms*\frac{1277}{1277+1024}*\frac{1024}{1277}=4.45ms$
B的虚拟时间为$10ms*\frac{1024}{1277+1024}*\frac{1024}{1024}=4.45ms$
可见,通过简单的权重转换,就可以把所有进程的虚拟时间调成一致(尽管其实际运行时间不一样),在选择下一个即将运行的进程的时候,只需要找到虚拟 时间最小的进程即可。
💡 PS. CFS有一点“公平不是平分”的味道了,它既能做到按需分配(权重不同则cpu usage不同),又能通过虚拟时间做到表面上的“completely fair”,以便OS去尽量公正平均地去选择下一个执行的进程,很聪明的想法
-
优先级反转
校长、系主任和jyy三人,校长想先sleep再拿锁,系主任一直死循环,jyy直接拿锁

等校长休息好想拿锁的时候,诶,问题出现了,jyy在持有互斥锁的时候被赶出了处理器,中等优先级的系主任一直在占用cpu,jyy无法释放锁 —— 那么,此 时校长由于拿不到锁,只能等待jyy,jyy又在等系主任,所以实际造成了高优先级的校长无法中断中优先级的系主任,即优先级反转
💡 PS. 校长因为拿不到锁而等待jyy这件事是没问题的,因为这是OS层面的语义,优先级再高被抢占时都只能等待
Lecture11、设备驱动原理与文件系统API
-
I/O设备的抽象
I/O设备的主要功能:输入和输出
常见的设备(打印机、终端、硬盘)都满足这个模型
所以操作系统提供的三个最基本的syscal
- read - 从设备某个指定的位置读出数据
- write - 向设备某个指定位置写入数据
- ioctl - 读取/设置设备的状态
-
设备驱动程序
把系统调用 (read/write/ioctl/…) “翻译” 成与设备寄存器的交互

-
文件系统介绍
motivation:设备在应用程序之间是需要共享的(多个进程并行打印,如何保证不混乱;每个CUDA应用程序都是一系列CUDA API的调用);另外,像磁盘这样的设备需要支持数据的持久化,如果让所有应用共享磁盘的话,一个程序bug操作系统就没了,所以我们需要设计一个文件系统以满足:
- 提供合理的API使多个应用程序能共享数据
- 提供一定的隔离,使bug的伤害不能任意扩大
文件系统:虚拟磁盘
- 磁盘(I/O设备)=一个可以读写的字节序列
- 虚拟磁盘(文件)=一个可以读写的动态字节序列
-
虚拟磁盘:命名管理
为了找到想要的虚拟磁盘,最直接的一个思路就是利用信息的局部性,讲虚拟磁盘组织成层次结构

文件系统的根:
- window:每个设备(驱动器)是一棵树

- UNIX:只有一个根
-
目录API(系统调用)
